7.1 BERT系列模型深度解析
BERT模型¶
学习目标¶
- 掌握BERT源代码中的关键类的定义.
- 掌握BERT源代码中的核心操作.
- 掌握BERT模型中参数量的计算.
BERT关键类的定义¶
- 关于BERT源代码的分析, 主要基于以下几个核心类进行:
- 第一: BertEmbeddings类(词嵌入层)
- 第二: BertSelfAttention类(多头自注意力层)
- 第三: BertSelfOutput类(自注意力输出层)
- 第四: BertIntermediate类(前馈全连接层)
- 第五: BertPooler类(CLS层)
- 第六: BertLMPredictionHead类(语言模型预测头)
- 第一: BertEmbeddings类(词嵌入层)
class BertEmbeddings(nn.Module):
"""Construct the embeddings from word, position and token_type embeddings."""
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))
if version.parse(torch.__version__) > version.parse("1.6.0"):
self.register_buffer(
"token_type_ids",
torch.zeros(self.position_ids.size(), dtype=torch.long),
persistent=False,
)
def forward(
self, input_ids=None, token_type_ids=None, position_ids=None, inputs_embeds=None, past_key_values_length=0
):
if input_ids is not None:
input_shape = input_ids.size()
else:
input_shape = inputs_embeds.size()[:-1]
seq_length = input_shape[1]
if position_ids is None:
position_ids = self.position_ids[:, past_key_values_length : seq_length + past_key_values_length]
# Setting the token_type_ids to the registered buffer in constructor where it is all zeros, which usually occurs
# when its auto-generated, registered buffer helps users when tracing the model without passing token_type_ids, solves
# issue #5664
if token_type_ids is None:
if hasattr(self, "token_type_ids"):
buffered_token_type_ids = self.token_type_ids[:, :seq_length]
buffered_token_type_ids_expanded = buffered_token_type_ids.expand(input_shape[0], seq_length)
token_type_ids = buffered_token_type_ids_expanded
else:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = inputs_embeds + token_type_embeddings
if self.position_embedding_type == "absolute":
position_embeddings = self.position_embeddings(position_ids)
embeddings += position_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
- 关键点回顾: 嵌入层的3部分都是通过nn.Embedding()来定义的, 而且都映射成768的维度, 最终加和.
- 第二: BertSelfAttention类(多头自注意力层)
class BertSelfAttention(nn.Module):
def __init__(self, config, position_embedding_type=None):
super().__init__()
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
f"heads ({config.num_attention_heads})"
)
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
self.position_embedding_type = position_embedding_type or getattr(
config, "position_embedding_type", "absolute"
)
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
self.max_position_embeddings = config.max_position_embeddings
self.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)
self.is_decoder = config.is_decoder
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view( *new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_value=None,
output_attentions=False,
):
mixed_query_layer = self.query(hidden_states)
# If this is instantiated as a cross-attention module, the keys
# and values come from an encoder; the attention mask needs to be
# such that the encoders padding tokens are not attended to.
is_cross_attention = encoder_hidden_states is not None
if is_cross_attention and past_key_value is not None:
# reuse k,v, cross_attentions
key_layer = past_key_value[0]
value_layer = past_key_value[1]
attention_mask = encoder_attention_mask
elif is_cross_attention:
key_layer = self.transpose_for_scores(self.key(encoder_hidden_states))
value_layer = self.transpose_for_scores(self.value(encoder_hidden_states))
attention_mask = encoder_attention_mask
elif past_key_value is not None:
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
else:
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
query_layer = self.transpose_for_scores(mixed_query_layer)
if self.is_decoder:
# if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
# Further calls to cross_attention layer can then reuse all cross-attention
# key/value_states (first "if" case)
# if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
# all previous decoder key/value_states. Further calls to uni-directional self-attention
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
# if encoder bi-directional self-attention `past_key_value` is always `None`
past_key_value = (key_layer, value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
seq_length = hidden_states.size()[1]
position_ids_l = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
position_ids_r = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
distance = position_ids_l - position_ids_r
positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
if self.position_embedding_type == "relative_key":
relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores
elif self.position_embedding_type == "relative_key_query":
relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_key
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
attention_probs = nn.functional.softmax(attention_scores, dim=-1)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view( *new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
if self.is_decoder:
outputs = outputs + (past_key_value,)
return outputs
- 关键点: 自注意力机制中的query, key, value在代码中本质上都是nn.Linear()定义的全连接层, 多头机制通过函数transpose_for_scores()来进行维度拆解和维度变换.
- 第三: BertSelfOutput类(自注意力输出层)
class BertSelfOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
- 核心点: 自注意力的输出层核心操作是一个变换方阵nn.Linear(768, 768), 外加LayerNorm和Dropout操作.
- 第四: BertIntermediate类(前馈全连接层)
class BertIntermediate(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = ACT2FN[config.hidden_act]
else:
self.intermediate_act_fn = config.hidden_act
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
- 核心点: 前馈全连接层的类名是BertIntermediate, 不要记成BertFeedForward. 本质上就是一个全连接层, 外加激活函数的操作.
- 第五: BertPooler类(CLS层)
class BertPooler(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states):
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
- 核心点: BertPooler的操作对象即BERT中的CLS, 即最后一层输出张量的第一个位置CLS的后续处理. 一般该类的输出用于分类任务.
- 第六: BertLMPredictionHead类(语言模型预测头)
class BertLMPredictionHead(nn.Module):
def __init__(self, config):
super().__init__()
self.transform = BertPredictionHeadTransform(config)
# The output weights are the same as the input embeddings, but there is
# an output-only bias for each token.
self.decoder = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
self.bias = nn.Parameter(torch.zeros(config.vocab_size))
# Need a link between the two variables so that the bias is correctly resized with `resize_token_embeddings`
self.decoder.bias = self.bias
def forward(self, hidden_states):
hidden_states = self.transform(hidden_states)
hidden_states = self.decoder(hidden_states)
return hidden_states
- 核心点: 语言模型预测头的核心操作就是slef.decoder, 用于将隐藏层维度映射到词表大小vocab_size上, 后续进行单词预测.
BERT模型中参数量的计算¶
-
详细理解BERT模型中参数量的计算, 可以更加深入细致的掌握BERT结构, 从细节到宏观都有更好的把握. 分三个部分进行计算:
- Embedding层的参数计算.
- Encoder层的参数计算.
- Pooling层的参数计算.
-
计算举例以bert-base-case模型为参考, 核心参数如下:
- 层数layer = 12
- 隐藏层维度hidden_size = 768
- 多头注意力数head = 12
- 参数总量 = 110M
Embedding层¶
- BERT的Embedding分为三个部分Token Embedding, Segment Embedding, Position Embedding. 其中Token Embedding包括词表V有30522个, 对应30522个单词(或token, 不同的语言模型数量不同). Segment Embedding包括2个取值, 分别表示当前token属于第1个句子, 还是第2个句子, 这是和BERT预训练的NSP任务直接相关的. Position Embedding包括512个取值(因为BERT要求编码序列的长度不超过512). 最后每种embedding都会把token映射到H维(当前默认为768)的隐向量中.
- 这3部分词嵌入的参数量为(30522 + 512 + 2) * 768 = 23835648
- 在完成词嵌入后, 每个位置的隐向量维度都是768, 还要经过一层LayerNorm, LayerNorm的参数就是均值和方差, 所以这个模块的参数量是768 * 2.
- 综上所述: Embedding层的参数总量就是(30522 + 512 + 2) * 768 + 768 * 2 = 23837184
Encoder层¶
- BERT中的Encoder是由12个Encoder Block堆叠在一起的, 而每一个Encoder Block的内部结构完全一样, 从下到上依次是:
- Multi-head Attention
- Add & Norm
- Feed Forward
- Add & Norm
- Multi-head Attention
- 每个Block包含12个head, 每个head拥有不同的3个自注意力矩阵Q, K, V, 通过矩阵乘法将上一层的输出跟着3个矩阵分别相乘, 得到新的Q, K, V向量. 需要注意的是这里有12个head, 所以每个head的每个矩阵都会把上一层的768维度向量的输出, 映射成768 / 12 = 64维的新向量, 最后通过concat操作进行拼接, 重新得到新的768维隐向量.
- 因此这里每个head的每个矩阵的参数包括weights = 768 * (768 / 12), bias = 768 / 12. 每个head同时拥有Q, K, V这3个矩阵, 每个Block又有12个head, 因此参数量 = 12 * 3 * (768 * (768 / 12) + 768 / 12) = 1771776.
- 在将12个head的输出concat到一起后, 还会经过一个全连接层的操作, 本质上是一个方阵映射, 这部分weight = 768 * 768, bias = 768.
- 因此整个Multi-head Attention模块的参数量 = 12 * 3 * (768 * (768 / 12) + 768 / 12) + 768 * 768 + 768 = 2362368
- Add & Norm
- Add本质上是跨层连接, 起到残差连接的作用, 没有额外的参数.
- Norm在这里指代LayerNorm操作, 参数包括均值和方差, 它接收的是上一层Multi-head Attention的768维的输出结果, 处理后的输出张量维度不变, 所以Norm总共有768 * 2个参数
- Feed Forward
- Feed Forward是前馈全连接层, 这里包括2层全连接层, 第1层全连接层会进行升维, 会把输入从当前维度(768)映射成4倍当前维度的中间层(3072), 第2层全连接层会进行降维, 会把4倍初始输入维度的中间层结果(3072)映射到初始维度(768).
- 第1层全连接层的weight = 768 * (768 * 4), bias = 768 * 4; 第2层全连接层的weight = (768 * 4) * 768, bias = 768.
- 综上所述, Feed Forward层的参数量 = 768 * (768 * 4) + 768 * 4 + (768 * 4) * 768 + 768 = 4722432
- Add & Norm
- 这里的Add & Norm和前面的论述一样, 参数量768 * 2.
- 综上所述, 整个Encoder部分拥有12个Block, 每个Block的参数前面已经详细计算过了, 因为总量是12 * (2362368 + 1536 + 4722432 + 1536) = 85054464
Pooling层¶
- Pooling层本质是一层全连接层, 它的输入是Encoder层输出的768维隐向量, 输出保持维度不变. 因此只包括weight = 768 * 768, bias = 768, 参数量 = 768 * 768 + 768 = 590592
结论: 整个BERT模型的参数量为前述3部分的总和, Embedding + Encoder + Pooling = 23837184 + 85054464 + 590592 = 109482240.
AlBERT模型¶
学习目标¶
- 掌握AlBERT模型的微调.
- 了解AlBERT模型的底层原理.
AlBERT模型微调¶
- 基于第5章5.2节的介绍, 此处展示一下AlBERT模型处理投满分项目的微调效果.
- 在模型构建部分引入的预训练模型从BERT换成AlBERT即可.
- 代码位置: /home/ec2-user/toutiao/albert/src/models/albert.py
import torch
import torch.nn as nn
import os
from transformers import AlbertModel, BertTokenizer, AlbertConfig
class Config(object):
def __init__(self, dataset):
self.model_name = "albert"
self.data_path = "/home/ec2-user/toutiao/albert/data/data/"
self.train_path = self.data_path + "train.txt" # 训练集
self.dev_path = self.data_path + "dev.txt" # 验证集
self.test_path = self.data_path + "test.txt" # 测试集
self.class_list = [
x.strip() for x in open(self.data_path + "class.txt").readlines()
] # 类别名单
self.save_path = "/home/ec2-user/toutiao/albert/src/saved_dic"
if not os.path.exists(self.save_path):
os.mkdir(self.save_path)
self.save_path += "/" + self.model_name + ".pt" # 模型训练结果
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 设备
# self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.num_epochs = 5 # epoch数
self.batch_size = 256 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-5 # 学习率
self.bert_path = "/home/ec2-user/toutiao/albert/data/albert_chinese_base/"
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
self.bert_config = AlbertConfig.from_pretrained(self.bert_path + '/config.json')
self.hidden_size = 768
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.albert = AlbertModel.from_pretrained(config.bert_path,config=config.bert_config)
for name, param in self.albert.named_parameters():
param.requires_grad = True
print(name)
self.fc = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
context = x[0] # 输入的句子
mask = x[2] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
_, pooled = self.albert(context, attention_mask=mask)
out = self.fc(pooled)
return out
- 调用:
cd /home/ec2-user/toutiao/albert/src/
python run.py --task train_albert
- 输出结果:
Loading data for Bert Model...
180000it [00:42, 4244.76it/s]
10000it [00:02, 3933.59it/s]
10000it [00:02, 4433.94it/s]
embeddings.word_embeddings.weight
embeddings.position_embeddings.weight
embeddings.token_type_embeddings.weight
embeddings.LayerNorm.weight
embeddings.LayerNorm.bias
encoder.embedding_hidden_mapping_in.weight
encoder.embedding_hidden_mapping_in.bias
encoder.albert_layer_groups.0.albert_layers.0.full_layer_layer_norm.weight
encoder.albert_layer_groups.0.albert_layers.0.full_layer_layer_norm.bias
encoder.albert_layer_groups.0.albert_layers.0.attention.query.weight
encoder.albert_layer_groups.0.albert_layers.0.attention.query.bias
encoder.albert_layer_groups.0.albert_layers.0.attention.key.weight
encoder.albert_layer_groups.0.albert_layers.0.attention.key.bias
encoder.albert_layer_groups.0.albert_layers.0.attention.value.weight
encoder.albert_layer_groups.0.albert_layers.0.attention.value.bias
encoder.albert_layer_groups.0.albert_layers.0.attention.dense.weight
encoder.albert_layer_groups.0.albert_layers.0.attention.dense.bias
encoder.albert_layer_groups.0.albert_layers.0.attention.LayerNorm.weight
encoder.albert_layer_groups.0.albert_layers.0.attention.LayerNorm.bias
encoder.albert_layer_groups.0.albert_layers.0.ffn.weight
encoder.albert_layer_groups.0.albert_layers.0.ffn.bias
encoder.albert_layer_groups.0.albert_layers.0.ffn_output.weight
encoder.albert_layer_groups.0.albert_layers.0.ffn_output.bias
pooler.weight
pooler.bias
Epoch [1/5]
57%|██████████████████████████████████████▋ | 400/704 [07:32<05:50, 1.15s/it]Iter: 400, Train Loss: 0.53, Train Acc: 86.33%, Val Loss: 0.51, Val Acc: 84.59%, Time: 0:07:51 *
100%|████████████████████████████████████████████████████████████████████| 704/704 [13:41<00:00, 1.17s/it]
Epoch [2/5]
57%|██████████████████████████████████████▋ | 400/704 [07:43<05:53, 1.16s/it]Iter: 400, Train Loss: 0.34, Train Acc: 89.45%, Val Loss: 0.37, Val Acc: 88.71%, Time: 0:21:43 *
100%|████████████████████████████████████████████████████████████████████| 704/704 [13:52<00:00, 1.18s/it]
Epoch [3/5]
57%|██████████████████████████████████████▋ | 400/704 [07:44<05:53, 1.16s/it]Iter: 400, Train Loss: 0.26, Train Acc: 92.58%, Val Loss: 0.33, Val Acc: 90.04%, Time: 0:35:36 *
100%|████████████████████████████████████████████████████████████████████| 704/704 [13:52<00:00, 1.18s/it]
Epoch [4/5]
57%|██████████████████████████████████████▋ | 400/704 [07:44<05:53, 1.16s/it]Iter: 400, Train Loss: 0.21, Train Acc: 95.70%, Val Loss: 0.32, Val Acc: 90.85%, Time: 0:49:29 *
100%|████████████████████████████████████████████████████████████████████| 704/704 [13:54<00:00, 1.18s/it]
Epoch [5/5]
57%|██████████████████████████████████████▋ | 400/704 [07:44<05:52, 1.16s/it]Iter: 400, Train Loss: 0.16, Train Acc: 96.48%, Val Loss: 0.33, Val Acc: 90.92%, Time: 1:03:24
100%|████████████████████████████████████████████████████████████████████| 704/704 [13:53<00:00, 1.18s/it]
Test Loss: 0.31, Test Acc: 90.73%
Precision, Recall and F1-Score...
precision recall f1-score support
finance 0.9213 0.8900 0.9054 1000
realty 0.9220 0.9100 0.9160 1000
stocks 0.8264 0.8520 0.8390 1000
education 0.9749 0.9340 0.9540 1000
science 0.8781 0.8430 0.8602 1000
society 0.8941 0.9120 0.9030 1000
politics 0.8644 0.8990 0.8814 1000
sports 0.9616 0.9760 0.9687 1000
game 0.9676 0.8950 0.9299 1000
entertainment 0.8761 0.9620 0.9171 1000
accuracy 0.9073 10000
macro avg 0.9087 0.9073 0.9075 10000
weighted avg 0.9087 0.9073 0.9075 10000
Confusion Matrix...
[[890 15 59 1 3 11 12 3 0 6]
[ 10 910 26 0 4 13 5 9 2 21]
[ 45 19 852 0 25 4 48 4 2 1]
[ 1 5 2 934 6 19 16 2 2 13]
[ 3 5 53 3 843 20 27 4 15 27]
[ 6 17 1 10 4 912 19 1 3 27]
[ 8 7 23 6 7 27 899 2 0 21]
[ 0 1 3 0 2 1 5 976 1 11]
[ 2 2 9 2 62 8 6 5 895 9]
[ 1 6 3 2 4 5 3 9 5 962]]
- 结论: 通过对AlBERT模型的微调, 得到测试集上的F1=90.73%, 这个分数相比较于BERT有接近3个百分点的下降, 还是比较显著的! 由此得出亲身实践的结论, 不要迷信任何模型, 因为基于标准数据集跑出来的效果, 在工业界落地中几乎不可能有"几乎一样优秀的"结果!
AlBERT模型的底层原理¶
- AlBERT模型源代码中有如下几个需要特别关注的类:
- 1: AlbertEmbeddings类
- 2: AlbertAttention类
- 3: AlbertLayer类
- 4: AlbertLayerGroup类
- 5: AlbertTransformer类
- 第1个: AlbertEmbeddings类
class AlbertEmbeddings(nn.Module):
"""
Construct the embeddings from word, position and token_type embeddings.
"""
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.embedding_size, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.embedding_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.embedding_size)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = nn.LayerNorm(config.embedding_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
if version.parse(torch.__version__) > version.parse("1.6.0"):
self.register_buffer(
"token_type_ids",
torch.zeros(self.position_ids.size(), dtype=torch.long),
persistent=False,
)
# Copied from transformers.models.bert.modeling_bert.BertEmbeddings.forward
def forward(
self, input_ids=None, token_type_ids=None, position_ids=None, inputs_embeds=None, past_key_values_length=0
):
if input_ids is not None:
input_shape = input_ids.size()
else:
input_shape = inputs_embeds.size()[:-1]
seq_length = input_shape[1]
if position_ids is None:
position_ids = self.position_ids[:, past_key_values_length : seq_length + past_key_values_length]
# Setting the token_type_ids to the registered buffer in constructor where it is all zeros, which usually occurs
# when its auto-generated, registered buffer helps users when tracing the model without passing token_type_ids, solves
# issue #5664
if token_type_ids is None:
if hasattr(self, "token_type_ids"):
buffered_token_type_ids = self.token_type_ids[:, :seq_length]
buffered_token_type_ids_expanded = buffered_token_type_ids.expand(input_shape[0], seq_length)
token_type_ids = buffered_token_type_ids_expanded
else:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = inputs_embeds + token_type_embeddings
if self.position_embedding_type == "absolute":
position_embeddings = self.position_embeddings(position_ids)
embeddings += position_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
- 第2个: AlbertAttention类
class AlbertAttention(nn.Module):
def __init__(self, config):
super().__init__()
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
f"heads ({config.num_attention_heads}"
)
self.num_attention_heads = config.num_attention_heads
self.hidden_size = config.hidden_size
self.attention_head_size = config.hidden_size // config.num_attention_heads
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
self.attention_dropout = nn.Dropout(config.attention_probs_dropout_prob)
self.output_dropout = nn.Dropout(config.hidden_dropout_prob)
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.pruned_heads = set()
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
self.max_position_embeddings = config.max_position_embeddings
self.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)
# Copied from transformers.models.bert.modeling_bert.BertSelfAttention.transpose_for_scores
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view( *new_x_shape)
return x.permute(0, 2, 1, 3)
def prune_heads(self, heads):
if len(heads) == 0:
return
heads, index = find_pruneable_heads_and_indices(
heads, self.num_attention_heads, self.attention_head_size, self.pruned_heads
)
# Prune linear layers
self.query = prune_linear_layer(self.query, index)
self.key = prune_linear_layer(self.key, index)
self.value = prune_linear_layer(self.value, index)
self.dense = prune_linear_layer(self.dense, index, dim=1)
# Update hyper params and store pruned heads
self.num_attention_heads = self.num_attention_heads - len(heads)
self.all_head_size = self.attention_head_size * self.num_attention_heads
self.pruned_heads = self.pruned_heads.union(heads)
def forward(self, hidden_states, attention_mask=None, head_mask=None, output_attentions=False):
mixed_query_layer = self.query(hidden_states)
mixed_key_layer = self.key(hidden_states)
mixed_value_layer = self.value(hidden_states)
query_layer = self.transpose_for_scores(mixed_query_layer)
key_layer = self.transpose_for_scores(mixed_key_layer)
value_layer = self.transpose_for_scores(mixed_value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
attention_scores = attention_scores + attention_mask
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
seq_length = hidden_states.size()[1]
position_ids_l = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
position_ids_r = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
distance = position_ids_l - position_ids_r
positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
if self.position_embedding_type == "relative_key":
relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores
elif self.position_embedding_type == "relative_key_query":
relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_key
# Normalize the attention scores to probabilities.
attention_probs = nn.functional.softmax(attention_scores, dim=-1)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.attention_dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.transpose(2, 1).flatten(2)
projected_context_layer = self.dense(context_layer)
projected_context_layer_dropout = self.output_dropout(projected_context_layer)
layernormed_context_layer = self.LayerNorm(hidden_states + projected_context_layer_dropout)
return (layernormed_context_layer, attention_probs) if output_attentions else (layernormed_context_layer,)
- 第3个: AlbertLayer类
class AlbertLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.chunk_size_feed_forward = config.chunk_size_feed_forward
self.seq_len_dim = 1
self.full_layer_layer_norm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.attention = AlbertAttention(config)
self.ffn = nn.Linear(config.hidden_size, config.intermediate_size)
self.ffn_output = nn.Linear(config.intermediate_size, config.hidden_size)
self.activation = ACT2FN[config.hidden_act]
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(
self, hidden_states, attention_mask=None, head_mask=None, output_attentions=False, output_hidden_states=False
):
attention_output = self.attention(hidden_states, attention_mask, head_mask, output_attentions)
ffn_output = apply_chunking_to_forward(
self.ff_chunk,
self.chunk_size_feed_forward,
self.seq_len_dim,
attention_output[0],
)
hidden_states = self.full_layer_layer_norm(ffn_output + attention_output[0])
return (hidden_states,) + attention_output[1:] # add attentions if we output them
def ff_chunk(self, attention_output):
ffn_output = self.ffn(attention_output)
ffn_output = self.activation(ffn_output)
ffn_output = self.ffn_output(ffn_output)
return ffn_output
- 第4个: AlbertLayerGroup类
class AlbertLayerGroup(nn.Module):
def __init__(self, config):
super().__init__()
self.albert_layers = nn.ModuleList([AlbertLayer(config) for _ in range(config.inner_group_num)])
def forward(
self, hidden_states, attention_mask=None, head_mask=None, output_attentions=False, output_hidden_states=False
):
layer_hidden_states = ()
layer_attentions = ()
for layer_index, albert_layer in enumerate(self.albert_layers):
layer_output = albert_layer(hidden_states, attention_mask, head_mask[layer_index], output_attentions)
hidden_states = layer_output[0]
if output_attentions:
layer_attentions = layer_attentions + (layer_output[1],)
if output_hidden_states:
layer_hidden_states = layer_hidden_states + (hidden_states,)
outputs = (hidden_states,)
if output_hidden_states:
outputs = outputs + (layer_hidden_states,)
if output_attentions:
outputs = outputs + (layer_attentions,)
return outputs # last-layer hidden state, (layer hidden states), (layer attentions)
- 第5个: AlbertTransformer类
class AlbertTransformer(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.embedding_hidden_mapping_in = nn.Linear(config.embedding_size, config.hidden_size)
self.albert_layer_groups = nn.ModuleList([AlbertLayerGroup(config) for _ in range(config.num_hidden_groups)])
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
output_attentions=False,
output_hidden_states=False,
return_dict=True,
):
hidden_states = self.embedding_hidden_mapping_in(hidden_states)
all_hidden_states = (hidden_states,) if output_hidden_states else None
all_attentions = () if output_attentions else None
head_mask = [None] * self.config.num_hidden_layers if head_mask is None else head_mask
for i in range(self.config.num_hidden_layers):
# Number of layers in a hidden group
layers_per_group = int(self.config.num_hidden_layers / self.config.num_hidden_groups)
# Index of the hidden group
group_idx = int(i / (self.config.num_hidden_layers / self.config.num_hidden_groups))
layer_group_output = self.albert_layer_groups[group_idx](
hidden_states,
attention_mask,
head_mask[group_idx * layers_per_group : (group_idx + 1) * layers_per_group],
output_attentions,
output_hidden_states,
)
hidden_states = layer_group_output[0]
if output_attentions:
all_attentions = all_attentions + layer_group_output[-1]
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(v for v in [hidden_states, all_hidden_states, all_attentions] if v is not None)
return BaseModelOutput(
last_hidden_state=hidden_states, hidden_states=all_hidden_states, attentions=all_attentions
)
AlBERT核心解密¶
- Emebdding因式分解(Factorized embedding parameterization)
class AlbertEncoder(nn.Module):
def __init__(self, config):
super(AlbertEncoder, self).__init__()
self.hidden_size = config.hidden_size
self.embedding_size = config.embedding_size
self.embedding_hidden_mapping_in = nn.Linear(self.embedding_size, self.hidden_size)
self.transformer = AlbertTransformer(config)
def forward(self, hidden_states, attention_mask=None, head_mask=None):
if self.embedding_size != self.hidden_size:
prev_output = self.embedding_hidden_mapping_in(hidden_states)
else:
prev_output = hidden_states
outputs = self.transformer(prev_output, attention_mask, head_mask)
return outputs # last-layer hidden state, (all hidden states), (all attentions)
- 在代码中的体现则是在Encoder层中增加了embedding_hidden_mapping_in层, 即增加了E * H的矩阵, 使得Embedding层和Encoder层解除绑定.
- 跨层参数共享(Cross-layer parameter sharing)
def _tie_or_clone_weights(self, first_module, second_module):
""" Tie or clone module weights depending of weither we are using TorchScript or not
"""
if self.config.torchscript:
first_module.weight = nn.Parameter(second_module.weight.clone())
else:
first_module.weight = second_module.weight
if hasattr(first_module, 'bias') and first_module.bias is not None:
first_module.bias.data = torch.nn.functional.pad(
first_module.bias.data,
(0, first_module.weight.shape[0] - first_module.bias.shape[0]),
'constant',
0
)
- 在Albert的源码中, 模型的参数共享是通过modeling_utils中PreTrainedModel的_tie_or_clone_weights实现的. PreTrainedModel作为基类实现了_tie_or_clone_weights, 它的子类在init_weight之后调用tie_weight实现参数共享, 而tie_weight的核心就是_tie_or_clone_weights.
RoBERTa模型¶
学习目标¶
- 掌握RoBERTa模型的架构.
- 理解RoBERTa模型的优化点.
- 掌握RoBERTa模型的微调.
RoBERTa模型的架构¶
-
原始论文<< RoBERTa: A Robustly Optimized BERT Pretraining Approach >>, 由FaceBook和华盛顿大学联合于2019年提出的模型.
-
从模型架构上看, RoBERTa和BERT完全一致, 核心模块都是基于Transformer的强大特征提取能力. 改进点主要集中在一些训练细节上.
- 第1点: More data
- 第2点: Larger batch size
- 第3点: Training longer
- 第4点: No NSP
- 第5点: Dynamic masking
- 第6点: Byte level BPE
RoBERTa模型的优化点¶
-
针对于上面提到的7点细节, 一一展开说明:
-
第1点: More data (更大的数据量)
- 原始BERT的训练语料采用了16GB的文本数据.
- RoBERTa采用了160GB的文本数据.
- 1: Books Corpus + English Wikipedia (16GB): BERT原文使用的之数据.
- 2: CC-News (76GB): 自CommonCrawl News数据中筛选后得到数据, 约含6300万篇新闻, 2016年9月-2019年2月.
- 3: OpenWebText (38GB): 该数据是借鉴GPT2, 从Reddit论坛中获取, 取点赞数大于3的内容.
- 4: Storie (31GB): 同样从CommonCrawl获取, 属于故事类数据, 而非新闻类.
- 第2点: Larger batch size (更大的batch size)
- BERT采用的batch size等于256.
- RoBERTa的训练在多种模式下采用了更大的batch size, 从256一直到最大的8000.
- 第3点: Training longer (更多的训练步数)
- RoBERTa的训练采用了更多的训练步数, 让模型充分学习数据中的特征.
- 第4点: No NSP (去掉NSP任务)
- 从2019年开始, 已经有越来越多的证据表明NSP任务对于大型预训练模型是一个负面作用, 因此在RoBERTa中直接取消掉NSP任务.
- 论文作者进行了多组对照试验:
- 1: Segment + NSP (即BERT模式). 输入包含两部分, 每个部分是来自同一文档或者不同文档的segment(segment是连续的多个句子), 这两个segment的token总数少于512, 预训练包含MLM任务和NSP任务.
- 2: Sentence pair + NSP (使用两个连续的句子 + NSP, 并采用更大的batch size). 输入也是包含两部分, 每个部分是来自同一个文档或者不同文档的单个句子, 这两个句子的token 总数少于512. 由于这些输入明显少于512个tokens, 因此增加batch size的大小, 以使tokens总数保持与SEGMENT-PAIR + NSP相似, 预训练包含MLM任务和NSP任务.
- 3: Full-sentences (如果输入的最大长度为512, 那么尽量选择512长度的连续句子; 如果跨越document, 就在中间加上一个特殊分隔符, 比如[SEP]; 该试验没有NSP). 输入只有一部分(而不是两部分), 来自同一个文档或者不同文档的连续多个句子, token总数不超过512. 输入可能跨越文档边界, 如果跨文档, 则在上一个文档末尾添加文档边界token, 预训练不包含NSP任务.
- 4: Document-sentences (和情况3一样, 但是步跨越document; 该实验没有NSP). 输入只有一部分(而不是两部分), 输入的构造类似于Full-sentences, 只是不需要跨越文档边界, 其输入来自同一个文档的连续句子, token总数不超过512. 在文档末尾附近采样的输入可以短于512个tokens, 因此在这些情况下动态增加batch size大小以达到与Full-sentecens相同的tokens总数, 预训练不包含NSP任务.
- 总的来说, 实验结果表明1 < 2 < 3 < 4.
- 真实句子过短的话, 不如拼接成句子段.
- 没有NSP任务更优.
- 不跨越document更优.
- 第5点: Dynamic masking (采用动态masking策略)
- 原始静态mask: 即BERT版本的mask策略, 准备训练数据时, 每个样本只会进行一次随机mask(因此每个epoch都是重复的), 后续的每个训练步都采用相同的mask方式, 这是原始静态mask.
- 动态mask: 并没有在预处理的时候执行mask, 而是在每次向模型提供输入时动态生成mask, 所以到底哪些tokens被mask掉了是时刻变化的, 无法提前预知的.
-
第6点: Byte level BPE (采用字节级别的Encoding)
- 基于char-level: 原始BERT的方式, 在中文场景下就是处理一个个的汉字.
- 基于bytes-level: 与char-level的区别在于编码的粒度是bytes, 而不是unicode字符作为sub-word的基本单位.
-
当采用bytes-level的BPE之后, 词表大小从3万(原始BERT的char-level)增加到5万. 这分别为BERT-base和BERT-large增加了1500万和2000万额外的参数. 之前有研究表明, 这样的做法在有些下游任务上会导致轻微的性能下降. 但论文作者相信: 这种统一编码的优势会超过性能的轻微下降.
- RoBERTa模型在多个标准数据集测试中展现了优秀的结果:
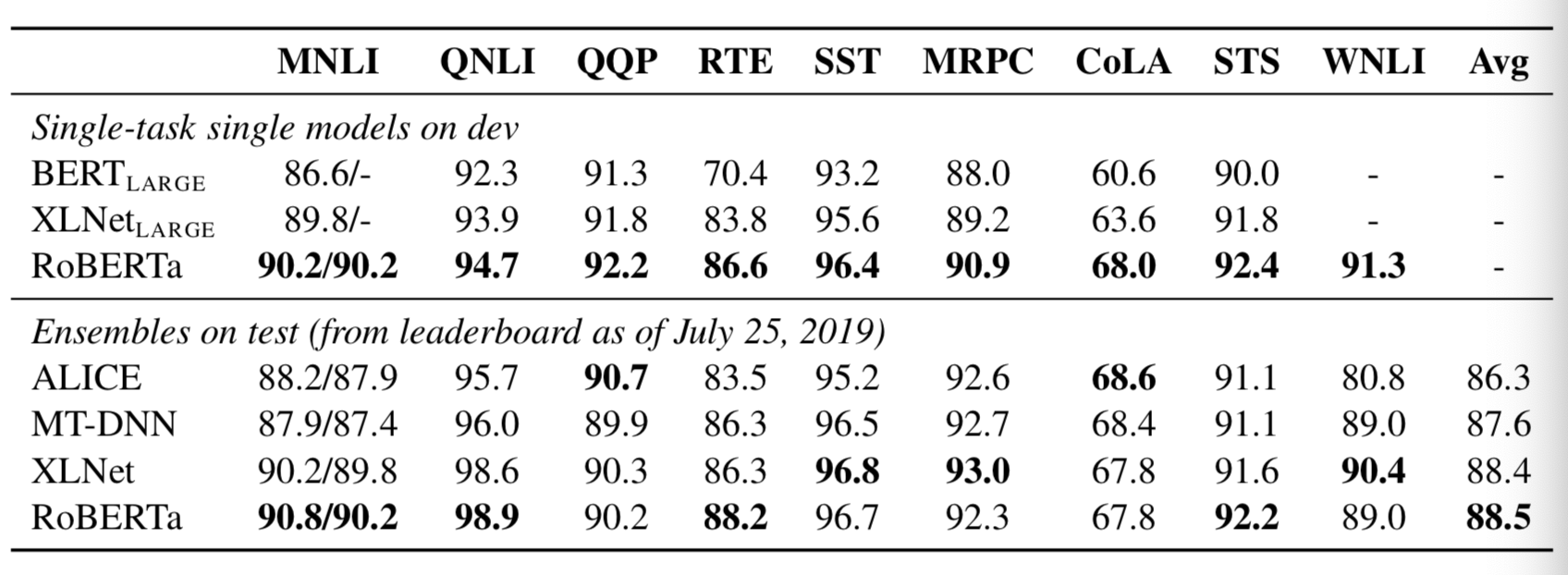
- RoBERTa模型在阅读理解任务中的表现则更加突出:
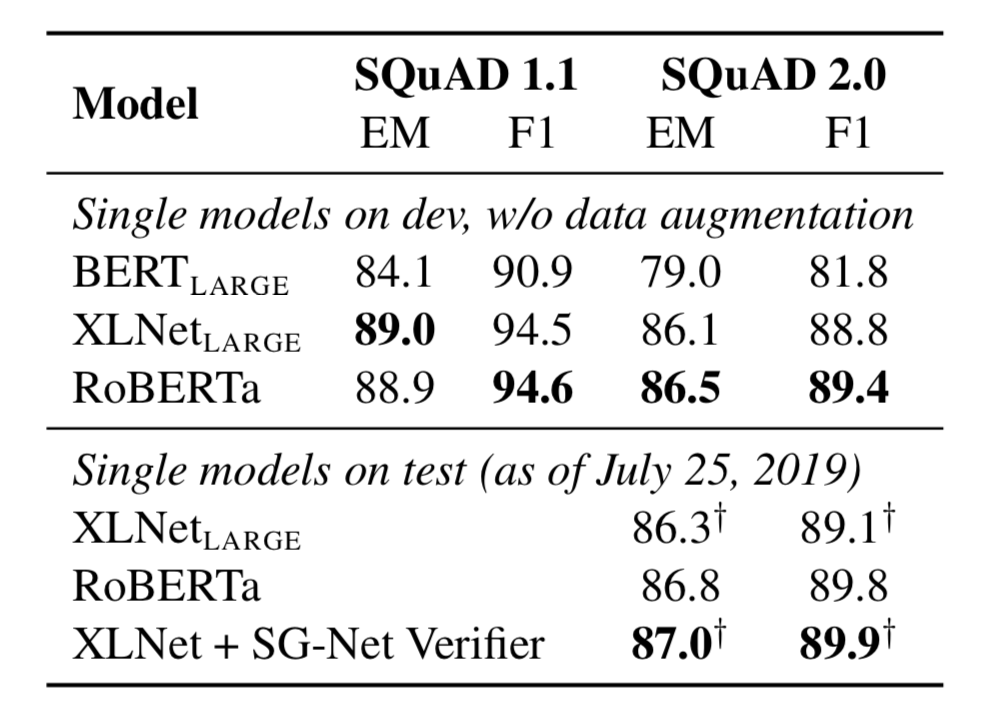
RoBERTa模型的微调¶
- 在投满分项目中, 应用预训练的RoBERTa模型实行微调:
import torch
import torch.nn as nn
import os
from transformers import BertModel, BertTokenizer, BertConfig
class Config(object):
def __init__(self, dataset):
self.model_name = "roberta"
self.data_path = "/home/ec2-user/ec2-user/zhudejun/bert/roberta/data/data/"
self.train_path = self.data_path + "train.txt" # 训练集
self.dev_path = self.data_path + "dev.txt" # 验证集
self.test_path = self.data_path + "test.txt" # 测试集
self.class_list = [
x.strip() for x in open(self.data_path + "class.txt").readlines()
] # 类别名单
self.save_path = "/home/ec2-user/ec2-user/zhudejun/bert/roberta/src/saved_dic"
if not os.path.exists(self.save_path):
os.mkdir(self.save_path)
self.save_path += "/" + self.model_name + ".pt" # 模型训练结果
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 设备
# self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.num_epochs = 5 # epoch数
self.batch_size = 256 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-5 # 学习率
self.bert_path = "/home/ec2-user/ec2-user/zhudejun/bert/roberta/data/roberta_chinese_wwm_ext/"
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
self.bert_config = BertConfig.from_pretrained(self.bert_path + '/config.json')
self.hidden_size = 768
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.roberta = BertModel.from_pretrained(config.bert_path,config=config.bert_config)
for name, param in self.roberta.named_parameters():
param.requires_grad = True
print(name)
self.fc = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
context = x[0] # 输入的句子
mask = x[2] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
_, pooled = self.roberta(context, attention_mask=mask)
out = self.fc(pooled)
return out
- 输出结果:
Loading data for Bert Model...
180000it [00:41, 4299.14it/s]
10000it [00:02, 3982.45it/s]
10000it [00:02, 4421.85it/s]
Epoch [1/5]
28%|██████████████████▊ | 200/704 [04:03<10:42, 1.27s/it]Iter: 200, Train Loss: 0.31, Train Acc: 89.45%, Val Loss: 0.26, Val Acc: 92.33%, Time: 0:04:25 *
57%|█████████████████████████████████████▌ | 400/704 [08:38<06:26, 1.27s/it]Iter: 400, Train Loss: 0.13, Train Acc: 96.09%, Val Loss: 0.23, Val Acc: 92.61%, Time: 0:09:00 *
85%|████████████████████████████████████████████████████████▎ | 600/704 [13:12<02:12, 1.27s/it]Iter: 600, Train Loss: 0.16, Train Acc: 94.53%, Val Loss: 0.2, Val Acc: 93.50%, Time: 0:13:34 *
100%|██████████████████████████████████████████████████████████████████| 704/704 [15:44<00:00, 1.34s/it]
Epoch [2/5]
28%|██████████████████▊ | 200/704 [04:13<10:43, 1.28s/it]Iter: 200, Train Loss: 0.2, Train Acc: 94.53%, Val Loss: 0.2, Val Acc: 93.77%, Time: 0:20:17
57%|█████████████████████████████████████▌ | 400/704 [08:45<06:24, 1.27s/it]Iter: 400, Train Loss: 0.11, Train Acc: 96.88%, Val Loss: 0.2, Val Acc: 93.83%, Time: 0:24:48
85%|████████████████████████████████████████████████████████▎ | 600/704 [13:15<02:11, 1.27s/it]Iter: 600, Train Loss: 0.086, Train Acc: 96.88%, Val Loss: 0.2, Val Acc: 93.70%, Time: 0:29:19
100%|██████████████████████████████████████████████████████████████████| 704/704 [15:44<00:00, 1.34s/it]
Epoch [3/5]
28%|██████████████████▊ | 200/704 [04:13<10:38, 1.27s/it]Iter: 200, Train Loss: 0.14, Train Acc: 94.92%, Val Loss: 0.2, Val Acc: 94.05%, Time: 0:36:01
57%|█████████████████████████████████████▌ | 400/704 [08:44<06:25, 1.27s/it]Iter: 400, Train Loss: 0.066, Train Acc: 97.66%, Val Loss: 0.21, Val Acc: 94.17%, Time: 0:40:32
85%|████████████████████████████████████████████████████████▎ | 600/704 [13:16<02:11, 1.27s/it]Iter: 600, Train Loss: 0.078, Train Acc: 97.66%, Val Loss: 0.22, Val Acc: 94.00%, Time: 0:45:04
100%|██████████████████████████████████████████████████████████████████| 704/704 [15:45<00:00, 1.34s/it]
Epoch [4/5]
28%|██████████████████▊ | 200/704 [04:14<10:42, 1.28s/it]Iter: 200, Train Loss: 0.09, Train Acc: 96.09%, Val Loss: 0.22, Val Acc: 94.20%, Time: 0:51:47
57%|█████████████████████████████████████▌ | 400/704 [08:45<06:25, 1.27s/it]Iter: 400, Train Loss: 0.032, Train Acc: 99.22%, Val Loss: 0.25, Val Acc: 93.72%, Time: 0:56:18
85%|████████████████████████████████████████████████████████▎ | 600/704 [13:17<02:11, 1.27s/it]Iter: 600, Train Loss: 0.047, Train Acc: 98.44%, Val Loss: 0.25, Val Acc: 94.11%, Time: 1:00:50
100%|██████████████████████████████████████████████████████████████████| 704/704 [15:45<00:00, 1.34s/it]
Epoch [5/5]
28%|██████████████████▊ | 200/704 [04:13<10:42, 1.27s/it]Iter: 200, Train Loss: 0.063, Train Acc: 97.66%, Val Loss: 0.26, Val Acc: 93.57%, Time: 1:07:32
57%|█████████████████████████████████████▌ | 400/704 [08:45<06:25, 1.27s/it]Iter: 400, Train Loss: 0.033, Train Acc: 99.61%, Val Loss: 0.27, Val Acc: 93.57%, Time: 1:12:04
85%|████████████████████████████████████████████████████████▎ | 600/704 [13:17<02:11, 1.27s/it]Iter: 600, Train Loss: 0.04, Train Acc: 98.05%, Val Loss: 0.24, Val Acc: 93.91%, Time: 1:16:36
100%|██████████████████████████████████████████████████████████████████| 704/704 [15:46<00:00, 1.34s/it]
Test Loss: 0.18, Test Acc: 94.30%
Precision, Recall and F1-Score...
precision recall f1-score support
finance 0.9498 0.9270 0.9383 1000
realty 0.9631 0.9400 0.9514 1000
stocks 0.9060 0.9060 0.9060 1000
education 0.9686 0.9570 0.9628 1000
science 0.9220 0.9100 0.9160 1000
society 0.9302 0.9460 0.9380 1000
politics 0.9054 0.9470 0.9257 1000
sports 0.9811 0.9840 0.9825 1000
game 0.9671 0.9410 0.9539 1000
entertainment 0.9400 0.9720 0.9558 1000
accuracy 0.9430 10000
macro avg 0.9433 0.9430 0.9430 10000
weighted avg 0.9433 0.9430 0.9430 10000
Confusion Matrix...
[[927 8 37 2 5 8 10 1 1 1]
[ 11 940 15 2 1 14 4 3 1 9]
[ 32 13 906 0 24 1 20 1 0 3]
[ 1 0 3 957 1 15 14 0 0 9]
[ 1 3 16 5 910 11 13 2 27 12]
[ 0 5 1 9 3 946 27 1 0 8]
[ 4 2 15 7 9 9 947 1 1 5]
[ 0 1 2 1 1 3 3 984 0 5]
[ 0 4 3 1 27 7 5 2 941 10]
[ 0 0 2 4 6 3 3 8 2 972]]
Time usage: 0:00:18
- 结论: RoBERTa模型在测试集上达到了94.30%的F1, 超过了BERT和AlBERT模型的表现, 非常优秀!
MacBert模型¶
学习目标¶
- 掌握MacBert模型的架构.
- 掌握MacBert模型的优化点.
- 掌握MacBert模型的微调.
MacBert模型的架构¶
-
MacBert模型由哈工大NLP实验室于2020年11月提出, 2021年5月发布应用, 是针对于BERT模型做了优化改良后的预训练模型.
-
<< Revisiting Pre-trained Models for Chinese Natural Language Processing >>, 通过原始论文题目也可以知道, MacBert是针对于中文场景下的BERT优化.
-
MacBert模型的架构和BERT大部分保持一致, 最大的变化有两点:
- 第一点: 对于MLM预训练任务, 采用了不同的MASK策略.
- 第二点: 删除了NSP任务, 替换成SOP任务.
MacBert模型的优化点¶
- 第一点: 对于MLM预训练任务, 采用了不同的MASK策略.
- 1: 使用了全词masked以及n-gram masked策略来选择tokens如何被遮掩, 从单个字符到4个字符的遮掩比例分别为40%, 30%, 20%, 10%
- 2: 原始BERT模型中的[MASK]出现在训练阶段, 但没有出现在微调阶段, 这会造成exposure bias的问题. 因此在MacBert中提出使用类似的单词来进行masked. 具体来说, 使用基于Word2Vec相似度计算包训练词向量, 后续利用这里面找近义词的功能来辅助mask, 比如以30%的概率选择了一个3-gram的单词进行masked, 则将在Word2Vec中寻找3-gram的近义词来替换, 在极少数情况下, 当没有符合条件的相似单词时, 策略会进行降级, 直接使用随机单词进行替换.
- 3: 使用15%的百分比对输入单词进行MASK, 其中80%的概率下执行策略2(即替换为相似单词), 10%的概率下替换为随机单词, 10%的概率下保留原始单词不变.
-
第二点: 删除了NSP任务, 替换成SOP任务.
-
第二点优化是直接借鉴了AlBERT模型中提出的SOP任务.
- 在NLP著名的难任务阅读理解中, MacBert展现出非常优秀的表现:
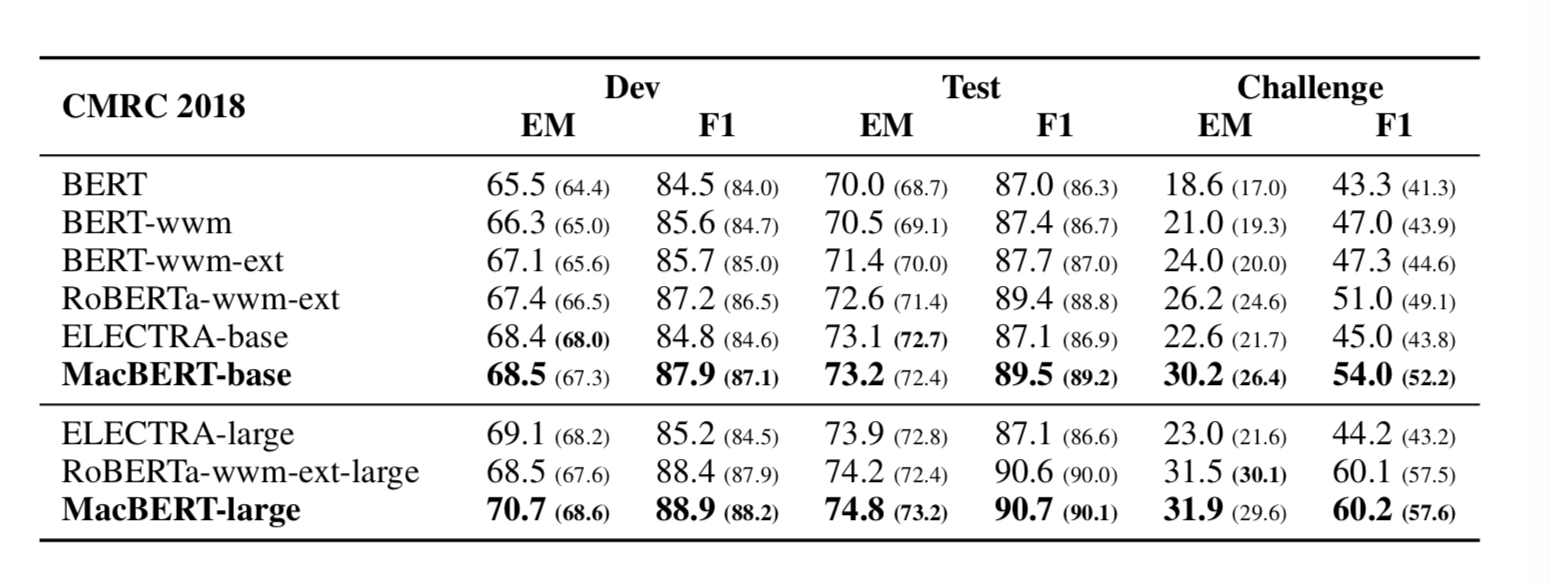
MacBert模型微调¶
- 在投满分项目中, 应用预训练的MacBert模型实行微调:
import torch
import torch.nn as nn
import os
from transformers import BertModel, BertTokenizer,BertConfig
class Config(object):
def __init__(self, dataset):
self.model_name = "macBert"
self.data_path = "/home/ec2-user/ec2-user/zhudejun/bert/macBert/data/data/"
self.train_path = self.data_path + "train.txt" # 训练集
self.dev_path = self.data_path + "dev.txt" # 验证集
self.test_path = self.data_path + "test.txt" # 测试集
self.class_list = [x.strip() for x in open(self.data_path + "class.txt").readlines()] # 类别名单
self.save_path = "/home/ec2-user/ec2-user/zhudejun/bert/macBert/src/saved_dic"
if not os.path.exists(self.save_path):
os.mkdir(self.save_path)
self.save_path += "/" + self.model_name + ".pt" # 模型训练结果
# 模型训练+预测的时候, 放开下一行代码, 在GPU上运行.
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 设备
# 模型量化的时候, 放开下一行代码, 在CPU上运行.
# self.device = 'cpu'
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.num_epochs = 3 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-5 # 学习率
self.bert_path = "/home/ec2-user/ec2-user/zhudejun/bert/macBert/data/macbert_chinese_base"
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
self.bert_config = BertConfig.from_pretrained(self.bert_path + '/config.json')
self.hidden_size = 768
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path, config=config.bert_config)
self.fc = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
context = x[0] # 输入的句子
mask = x[2] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
_, pooled = self.bert(context, attention_mask=mask)
out = self.fc(pooled)
return out
- 输出结果:
Loading data for Bert Model...
180000it [00:42, 4252.41it/s]
10000it [00:02, 3928.04it/s]
10000it [00:02, 4353.32it/s]
Epoch [1/3]
14%|█████████▏ | 200/1407 [02:00<12:33, 1.60it/s]Iter: 200, Train Loss: 0.25, Train Acc: 92.19%, Val Loss: 0.3, Val Acc: 91.26%, Time: 0:02:19 *
28%|██████████████████▍ | 400/1407 [04:28<10:55, 1.54it/s]Iter: 400, Train Loss: 0.38, Train Acc: 89.06%, Val Loss: 0.24, Val Acc: 92.33%, Time: 0:04:49 *
43%|███████████████████████████▋ | 600/1407 [06:59<08:46, 1.53it/s]Iter: 600, Train Loss: 0.25, Train Acc: 91.41%, Val Loss: 0.23, Val Acc: 92.55%, Time: 0:07:20 *
57%|████████████████████████████████████▉ | 800/1407 [09:30<06:36, 1.53it/s]Iter: 800, Train Loss: 0.15, Train Acc: 93.75%, Val Loss: 0.21, Val Acc: 93.09%, Time: 0:09:51 *
71%|█████████████████████████████████████████████▍ | 1000/1407 [12:00<04:24, 1.54it/s]Iter: 1000, Train Loss: 0.18, Train Acc: 92.97%, Val Loss: 0.21, Val Acc: 92.92%, Time: 0:12:19
85%|██████████████████████████████████████████████████████▌ | 1200/1407 [14:28<02:14, 1.53it/s]Iter: 1200, Train Loss: 0.2, Train Acc: 92.97%, Val Loss: 0.21, Val Acc: 93.28%, Time: 0:14:49 *
100%|███████████████████████████████████████████████████████████████▋| 1400/1407 [16:58<00:04, 1.54it/s]Iter: 1400, Train Loss: 0.3, Train Acc: 90.62%, Val Loss: 0.21, Val Acc: 93.29%, Time: 0:17:17
100%|████████████████████████████████████████████████████████████████| 1407/1407 [17:20<00:00, 1.35it/s]
Epoch [2/3]
14%|█████████▏ | 200/1407 [02:10<13:03, 1.54it/s]Iter: 200, Train Loss: 0.19, Train Acc: 92.97%, Val Loss: 0.2, Val Acc: 93.52%, Time: 0:19:52 *
28%|██████████████████▍ | 400/1407 [04:41<10:59, 1.53it/s]Iter: 400, Train Loss: 0.25, Train Acc: 90.62%, Val Loss: 0.2, Val Acc: 93.72%, Time: 0:22:23 *
43%|███████████████████████████▋ | 600/1407 [07:11<08:46, 1.53it/s]Iter: 600, Train Loss: 0.16, Train Acc: 92.97%, Val Loss: 0.19, Val Acc: 93.92%, Time: 0:24:54 *
57%|████████████████████████████████████▉ | 800/1407 [09:42<06:34, 1.54it/s]Iter: 800, Train Loss: 0.068, Train Acc: 98.44%, Val Loss: 0.2, Val Acc: 93.75%, Time: 0:27:22
71%|█████████████████████████████████████████████▍ | 1000/1407 [12:10<04:24, 1.54it/s]Iter: 1000, Train Loss: 0.11, Train Acc: 96.88%, Val Loss: 0.23, Val Acc: 93.32%, Time: 0:29:50
85%|██████████████████████████████████████████████████████▌ | 1200/1407 [14:38<02:14, 1.53it/s]Iter: 1200, Train Loss: 0.16, Train Acc: 92.97%, Val Loss: 0.21, Val Acc: 93.63%, Time: 0:32:18
100%|███████████████████████████████████████████████████████████████▋| 1400/1407 [17:06<00:04, 1.54it/s]Iter: 1400, Train Loss: 0.26, Train Acc: 93.75%, Val Loss: 0.2, Val Acc: 93.93%, Time: 0:34:46
100%|████████████████████████████████████████████████████████████████| 1407/1407 [17:28<00:00, 1.34it/s]
Epoch [3/3]
14%|█████████▏ | 200/1407 [02:09<13:05, 1.54it/s]Iter: 200, Train Loss: 0.13, Train Acc: 96.88%, Val Loss: 0.21, Val Acc: 93.92%, Time: 0:37:18
28%|██████████████████▍ | 400/1407 [04:37<10:54, 1.54it/s]Iter: 400, Train Loss: 0.18, Train Acc: 95.31%, Val Loss: 0.2, Val Acc: 94.11%, Time: 0:39:46
43%|███████████████████████████▋ | 600/1407 [07:05<08:46, 1.53it/s]Iter: 600, Train Loss: 0.076, Train Acc: 96.88%, Val Loss: 0.2, Val Acc: 94.06%, Time: 0:42:13
57%|████████████████████████████████████▉ | 800/1407 [09:33<06:35, 1.54it/s]Iter: 800, Train Loss: 0.023, Train Acc: 99.22%, Val Loss: 0.22, Val Acc: 93.69%, Time: 0:44:42
71%|█████████████████████████████████████████████▍ | 1000/1407 [12:01<04:23, 1.54it/s]Iter: 1000, Train Loss: 0.069, Train Acc: 97.66%, Val Loss: 0.23, Val Acc: 93.64%, Time: 0:47:10
85%|██████████████████████████████████████████████████████▌ | 1200/1407 [14:29<02:14, 1.54it/s]Iter: 1200, Train Loss: 0.13, Train Acc: 95.31%, Val Loss: 0.23, Val Acc: 93.25%, Time: 0:49:37
100%|███████████████████████████████████████████████████████████████▋| 1400/1407 [16:57<00:04, 1.53it/s]Iter: 1400, Train Loss: 0.18, Train Acc: 95.31%, Val Loss: 0.21, Val Acc: 93.99%, Time: 0:52:05
100%|████████████████████████████████████████████████████████████████| 1407/1407 [17:19<00:00, 1.35it/s]
Test Loss: 0.18, Test Acc: 94.48%
Precision, Recall and F1-Score...
precision recall f1-score support
finance 0.9498 0.9280 0.9388 1000
realty 0.9506 0.9620 0.9563 1000
stocks 0.9059 0.9050 0.9055 1000
education 0.9680 0.9670 0.9675 1000
science 0.9078 0.9250 0.9163 1000
society 0.9441 0.9290 0.9365 1000
politics 0.9209 0.9320 0.9264 1000
sports 0.9889 0.9800 0.9844 1000
game 0.9686 0.9560 0.9623 1000
entertainment 0.9451 0.9640 0.9545 1000
accuracy 0.9448 10000
macro avg 0.9450 0.9448 0.9448 10000
weighted avg 0.9450 0.9448 0.9448 10000
Confusion Matrix...
[[928 12 42 2 4 3 7 1 1 0]
[ 10 962 7 1 3 7 3 2 0 5]
[ 27 20 905 0 27 1 19 0 0 1]
[ 1 1 2 967 5 7 10 0 0 7]
[ 1 0 11 4 925 13 9 1 25 11]
[ 2 9 3 11 4 929 26 0 3 13]
[ 4 2 23 6 14 14 932 1 0 4]
[ 2 2 2 2 1 1 1 980 0 9]
[ 0 0 2 2 29 3 1 1 956 6]
[ 2 4 2 4 7 6 4 5 2 964]]
Time usage: 0:00:18
- 结论: 采用macBert模型后, 在测试集上得到94.48%的高分, 超越了BERT, AlBERT, RoBERTa模型, 展现出了非常优秀的模型气质!!!
SpanBERT模型¶
学习目标¶
- 掌握SpanBERT模型的架构.
- 掌握SpanBERT模型的优化点.
SpanBERT模型的架构¶
- 论文的主要贡献有3点:
- 1: 提出了更好的Span Mask方案, 再次展示了随机遮掩连续一段tokens比随机遮掩单个token要好.
- 2: 通过加入了Span Boundary Objective(SBO)训练任务, 增强了BERT的性能, 特别在一些和Span适配的任务, 如抽取式问答.
- 3: 用实验数据获得了和XLNet一致的结果, 发现去除掉NSP任务, 直接用连续一长句训练效果更好.
- SpanBERT的架构图如下:
- 架构图中可以清晰的展示论文的核心贡献点:
- Span Masking
- Span Boundary Objective
Span Masking¶
-
关于创新的MASK机制, 一般来说都是相对于原始BERT的基准进行改进. 对于BERT, 训练时会随机选取整句中的最小输入单元token来进行遮掩, 中文场景下本质上就是进行字级别的MASK. 但是这种方式会让本来应该有强相关的一些连在一起的字词, 在训练时被割裂开了.
-
那么首先想到的做法: 既然能遮掩字, 那么能不能直接遮掩整个词呢? 这就是BERT-WWM模型的思想.
原始输入: 使用语言模型来预测下一个词的概率.
原始BERT: 使用语言[MASK]型来[MASK]测下一个词的[MASK]率.
BERT-WWM: 使用语言[MASK][MASK]来[MASK][MASK]下一个词的[MASK][MASK].
- 引申: 百度著名的ERNIE模型中, 直接引入命名实体(Named Entity)的外部知识, 进行整个实体的遮掩, 进行训练.
-
综合上面所说, 会更自然的想到, 既然整词的MASK, 那么如果拥有词的边界信息会不会让模型的能力更上一层楼呢? SpanBERT给出的是肯定的回答!!!
-
论文中关于span的选择, 走了这样一个流程:
- 第一步: 根据几何分布, 先随机选择一个**span长度**.
- 第二步: 再根据均匀分布随机选择这一段的**起始位置**.
- 第三步: 最后根据前两步的start和length直接进行MASK.
- 结论: 论文中详细论证了按照上述算法进行MASK, 随机被遮掩的文本平均长度等于3.8
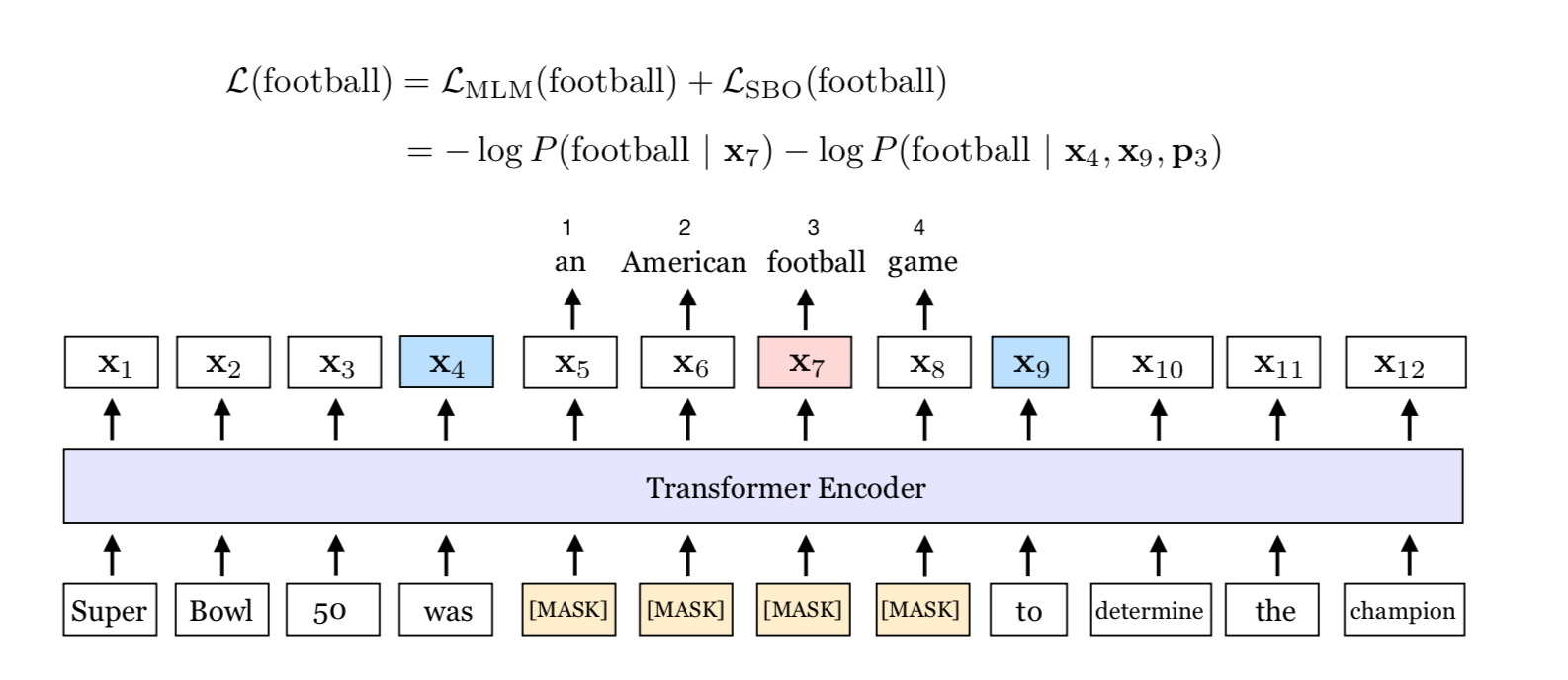
Span Boundary Objective(SBO)¶
- SBO任务是本篇论文最核心的创新点, 希望通过增加这个预训练任务, 可以让被遮掩的Span Boundary的词向量, 能够学习到Span内部的信息.
-
具体的做法: 在训练时取Span前后边界的两个词, 需要注意这两个词不在Span内, 然后用这两个词向量加上Span中被MASK掉的词的位置向量, 来预测原词.
-
更详细的操作如下, 即将词向量和位置向量进行拼接, 经过GeLU激活和LayerNorm处理, 连续经过两个全连接层, 得到最终的输出张量:

- 最后预测Span中原词的时候会得到一个损失, 这就是SBO任务的损失; 再将其和BERT自身的MLM任务的损失进行加和, 共同作为SpanBERT的目标损失函数进行训练:
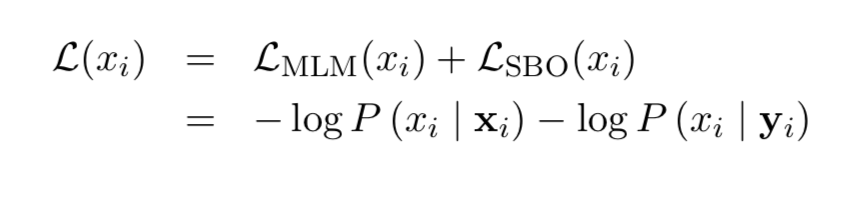
NSP任务反思¶
- 为什么选择Single Sentence而不是BERT的Two Sentence?
- 1: 训练文本的长度更大, 可以学会长程依赖.
- 2: 对于NSP的负样本, 基于另一个主题文档的句子来预测单词, 会给MLM任务引入很大的噪声.
- 3: AlBERT模型已经给出了论证, 因为NSP任务太简单了.
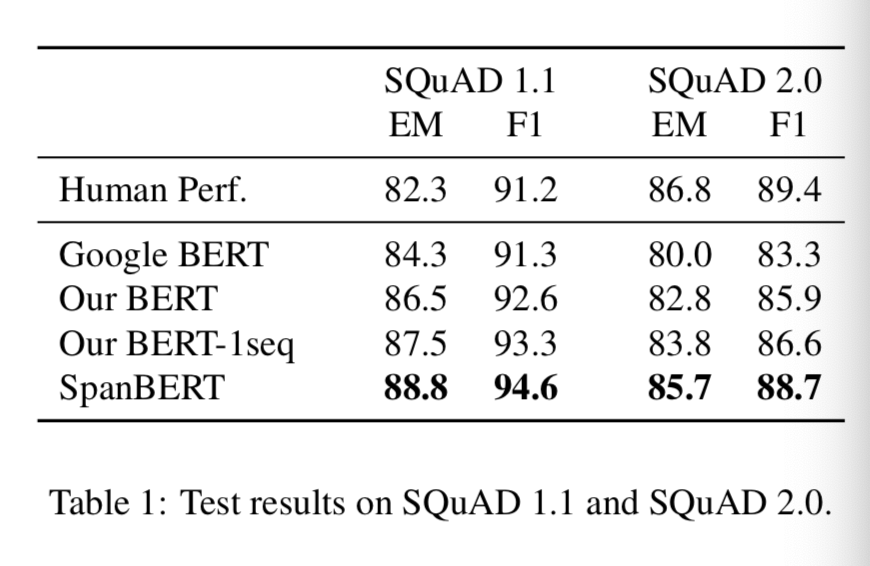
SpanBERT结果¶
- SpanBERT在NLP的难任务阅读理解任务中得到了优秀的结果:
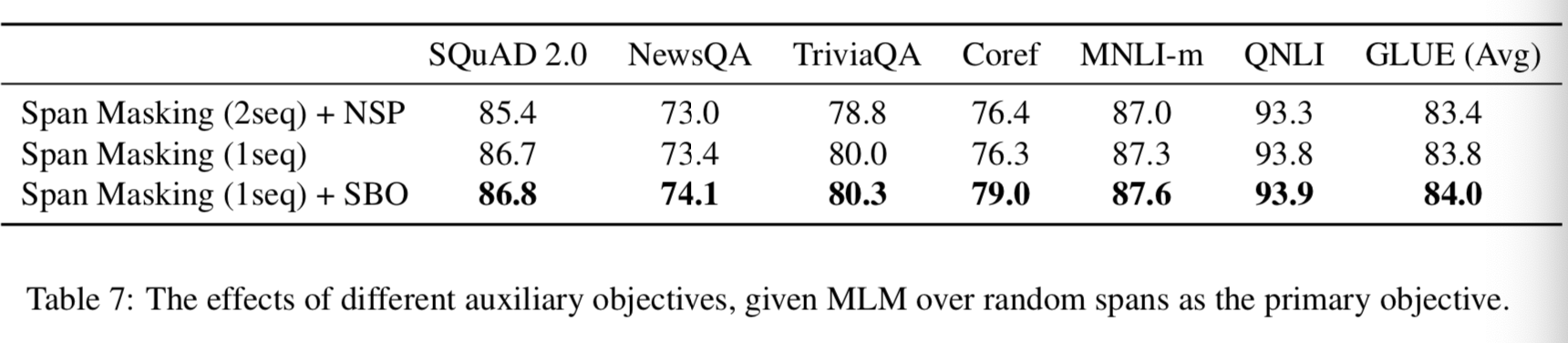
- 训练任务中, 选取Span Masking和SBO结合的手段, 可以得到最优的结果, 尤其在指代消解任务上得到了大幅度的提升:
FinBERT模型¶
学习目标¶
- 掌握FinBERT模型的架构.
- 掌握FinBERT模型的优化点.
- 掌握FinBERT模型的应用.
FinBERT模型的架构¶
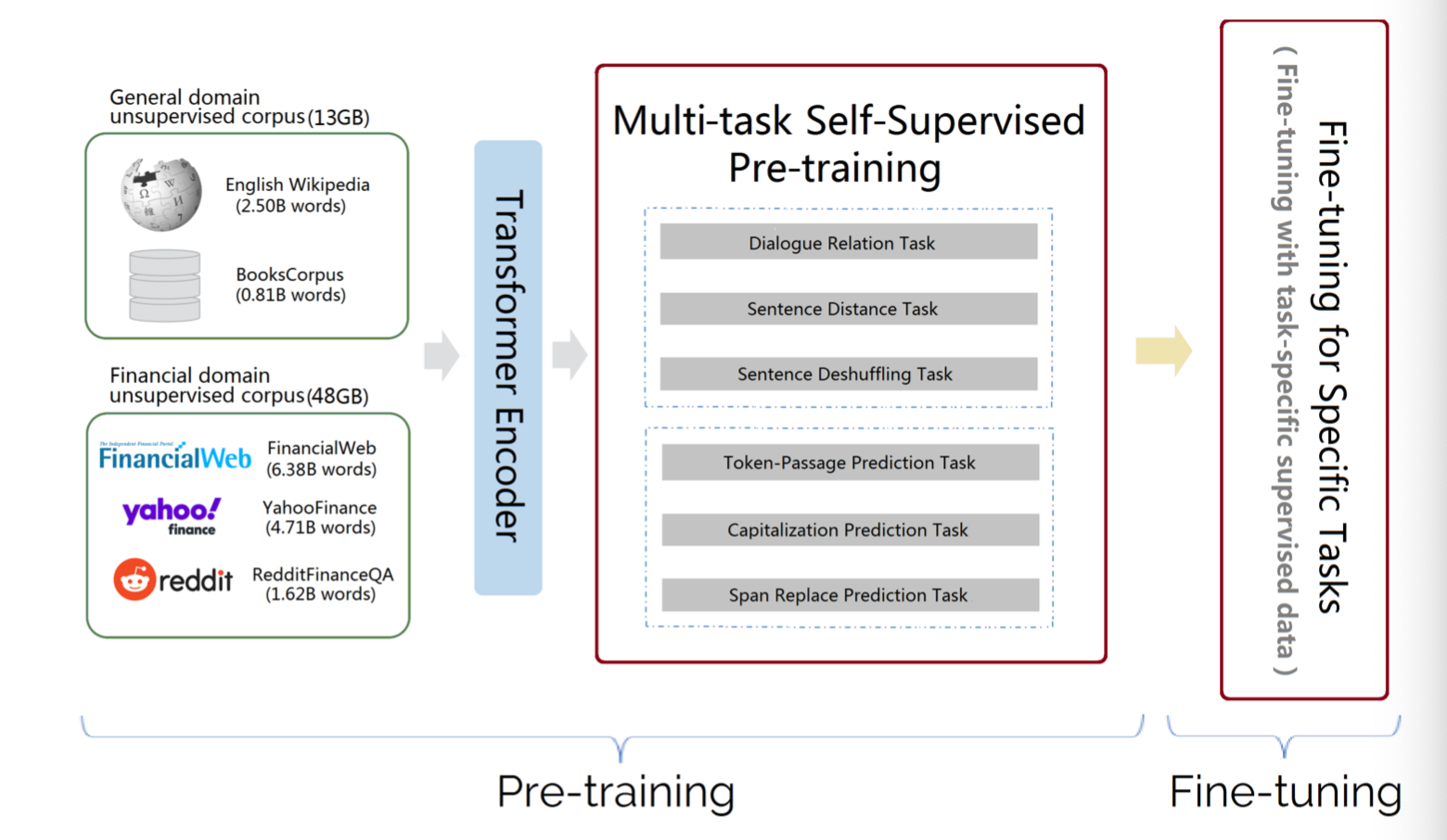
- 首先展示一下FinBERT的架构图, 分为Pre-training和Fine-tuning两大部分, 在通用语料和金融专属语料上, 引入多个预训练任务用以增强模型的能力, 最后在特定任务上进行微调即可.
-
首先回顾一下原始论文<< FinBERT: Financial Sentiment Analysis with Pre-trained Language Models >>, 当前许多情感分类解决方案在产品或电影评论数据集中获得了很高的分数, 但是在金融领域这些方法的性能却大大落后. 出现这种差距的根本原因是垂直领域的专用语言表达, 它降低了现有模型的适用性, 并且缺乏高质量的标记数据来学习特定领域的积极, 消极, 中性表达的新的上下文.
-
论文探讨了NLP迁移学习在金融领域情感分类任务中的有效性, 提出了一个基于BERT的新语言模型FinBERT, 将一个金融领域情感分类在FinancialPhrasebank数据集中的最新性能提高了14个百分点, 直接拿下SOTA天花板级别的表现!!!
- 背景介绍: 由于互联网时代每天都要产生数量空前的文本数据, 因此分析来自医学领域, 金融领域, 法律领域的大量文本更具显示意义. 在这些垂直领域中应用监督方法比应用于更一般化的文本困难得多. 主要困难有两点:
- 第一点: 利用基于神经网络的深度学习技术需要大量的标注数据, 而垂直领域(典型的是医疗, 金融, 法律等)的标注数据需要昂贵的人工成本.
- 第二点: 在一般语料库上训练的NLP模型不适用于监督任务, 因为垂直领域的文本有专门的语言习惯和独特的词汇表达.
FinBERT模型的优化点¶
- 关于FinBERT具体的优化任务, 我们一一列举如下:
- Span Replace Prediction Task: 这个任务的技巧来源于T5和SpanBERT, 就是将文本中的连续一段MASK掉, 然后用这一段前面一个位置的token(start-1), 后面一个位置的token(end+1), 被MASK掉的token的位置向量position_x, 这三个张量信息共同预测该位置的单词是什么.
- Capitalization Prediction Task: 预测单词的大小写, 因为一些专有名词是大写的, 所以这个任务可能对NER任务更加有用.
- Token-Passage Prediction Task: 预测当前句子中的这个单词是否会出现在该文档的其他句子中, 这种词往往是常见词, 或该文档的主题词.
- Sentence Deshuffling Task: 将句子拆分成几个片段, 然后打乱顺序, 最后预测原始顺序.
- Sentence Distance Task: 是对BERT中NSP任务的推广. BERT中的NSP只预测两个句子是否连续. SDT需要预测三种情况:
- 情况1: 两个句子连续, 且同属一个文档.
- 情况2: 两个句子不连续, 且同属一个文档.
- 情况3: 两个句子不属于一个文档.
-
为了训练金融领域的模型, 需要大量垂直领域的数据, 论文中所涉及到的数据集有:
- FinancialWeb: 从CommonCrawl News数据集中提取到的一个金融新闻数据集.
- FinSBD-2019 dataset: 一个用于金融句子边界检测任务(Financial Sentence Boundary Detection)的数据集, 任务是从文本中提取出金融相关的语句.
- Financial Phrasebank dataset: 一个金融情感分析数据集.
- FiQA SA dataset: 这个数据集出自WWW18, 包含金融新闻头条和金融微博文本, label有命名实体, 情感分数以及aspect.
- Financial QA dataset: 一个金融领域的问答数据集, 爬取自Stack Exchange投资主体的博文.
-
FinBERT模型在几个主流金融垂直领域的数据集上, 得到了远超BERT的表现, 非常出众!

FinBERT模型的应用¶
- 因为投满分项目并不是金融领域的垂直应用, 所以直接调用预训练模型效果不会好, 在此展示模型是如何应用的.
from transformers import BertTokenizer, BertForSequenceClassification
import numpy as np
finbert = BertForSequenceClassification.from_pretrained('./finbert-uncased', num_labels=3)
tokenizer = BertTokenizer.from_pretrained('./finbert-uncased')
sentences = ["there is a shortage of capital, and we need extra financing",
"growth is strong and we have plenty of liquidity",
"there are doubts about our finances",
"profits are flat"]
inputs = tokenizer(sentences, return_tensors='pt', padding=True)
outputs = finbert( **inputs)[0]
labels = {0:'neutral', 1:'positive', 2:'negative'}
for idx, sent in enumerate(sentences):
print(sent, '----', labels[np.argmax(outputs.detach().numpy()[idx])])
- 输出结果:
there is a shortage of capital, and we need extra financing ---- negative
growth is strong and we have plenty of liquidity ---- positive
there are doubts about our finances ---- negative
profits are flat ---- neutral
K-BERT模型¶
学习目标¶
- 掌握K-BERT模型的架构.
- 掌握K-BERT模型的优化点.
K-BERT模型的架构¶
K-BERT模型背景¶
-
由北京大学和腾讯研究院于2020年提出的新模型, 原始论文<< K-BERT: Enabling Language Representation with Knowledge Graph >>.
-
预训练的语言表示模型(如BERT)从大型语料库捕获一般的语言表示, 但缺乏领域特定的知识. 在阅读领域文本时, 专家会利用相关知识进行推理. 为了使机器能够实现这一功能, 论文提出了一种基于知识图的支持知识的语言表示模型(K-BERT), 该模型将三元组作为领域知识注入到句子中.
-
知识噪声: 过多的知识掺入会使句子偏离正确的含义, 这就是知识噪声问题. 为了克服知识噪声问题, K-BERT引入了软定位和可见矩阵来限制知识的影响.
-
由于K-BERT能够从预先训练好的BERT中加载模型参数, 因此不需要进行单独的预训练, 只需装备一个KG, K-BERT就可以很容易地将领域知识注入到模型中. 论文中详细调查在12个NLP任务中发现了有希望的结果. 特别是在特定领域的任务(包括金融, 法律, 医学)中, K-BERT的表现明显优于BERT, 这表明K-BERT是解决需要专家参与的知识驱动问题的最佳选择.
-
近两年, 谷歌BERT等无监督预训练语言表示模型在多个NLP任务中均取得了可喜的成果. 这些模型在大规模开放域语料库上进行了预训练, 以获得通用的语言表示形式, 然后在特定的下游任务中进行了微调, 以吸收特定领域的知识. 但是, 由于预训练和微调之间的领域差异, 这些模型在知识驱动的任务上表现不佳. 例如, 在医疗领域处理电子病历(EMR)分析任务时, 经过Wikipedia预训练的BERT无法充分发挥其价值.
-
当阅读特定领域文本时, 普通人只能根据其上下文理解单词, 而专家则可以利用相关领域知识进行推断. 目前公开的BERT, GPT, XLNet等预训练模型均是在开放领域语料预训练得到的. 其就像一个普通人, 虽然能够读懂通用文本, 但是对于专业领域文本时却缺乏一定的背景知识.
-
解决这一问题的一个方法是使用专业语料预训练模型, 但是预训练的过程是十分耗时和耗计算资源的, 普通研究者通常难以实现. 例如, 如果我们希望模型获得“新冠疫苗可以预防和降低病人的重症住院率”的知识, 则在训练语料库中需要大量同时出现“新冠疫苗”和“重症住院率”的句子. 不仅如此, 通过领域语料预训练的方式引入专家知识, 其可解释性和可控性较差.
-
随着知识细化为结构化形式, 许多领域的KG都被构建起来. 例如医学领域的SNOMED-CT, 中国概念的HowNet. 如果KG可以集成到预训练语言模型中, 它将为模型配备领域知识, 从而提高模型在特定领域任务上的性能, 同时降低大规模的预训练成本. 此外, 知识图谱具有很高的可解释性, 因为可以手动编辑注入的知识.
-
目前, 将知识图谱与语言模型结合的研究有哪些呢? 最具代表性的就是百度的ERNIE, 其使用一个独立的TransE 算法获得实体向量, 然后再将实体向量嵌入到BERT中. 百度ERNIE的工作很有借鉴意义, 但是仍然存在一些可改进的地方, 例如:
- 1: 知识图谱中的关系信息没有被用到.
- 2: 实体向量和词向量是使用不同的方法得到的, 可能存在空间的不一致.
- 3: 对于实体数量巨大的大规模知识图谱, 实体向量表将占据很大的内存.
- 引申问题: 将过多的知识引入到语言表示模型中, 可能会改变原来句子的含义, 称为知识噪声(KN)问题. 为了解决以上问题, 研究人员尝试不区分实体向量和词向量, 而是使用统一的向量空间将知识注入语言表示模型中.
K-BERT模型架构¶
- K-BERT模型的架构图如下:
- 第一层: 知识层
- 第二层: 嵌入层
- 第三层: 视图层
- 第四层: 掩码层
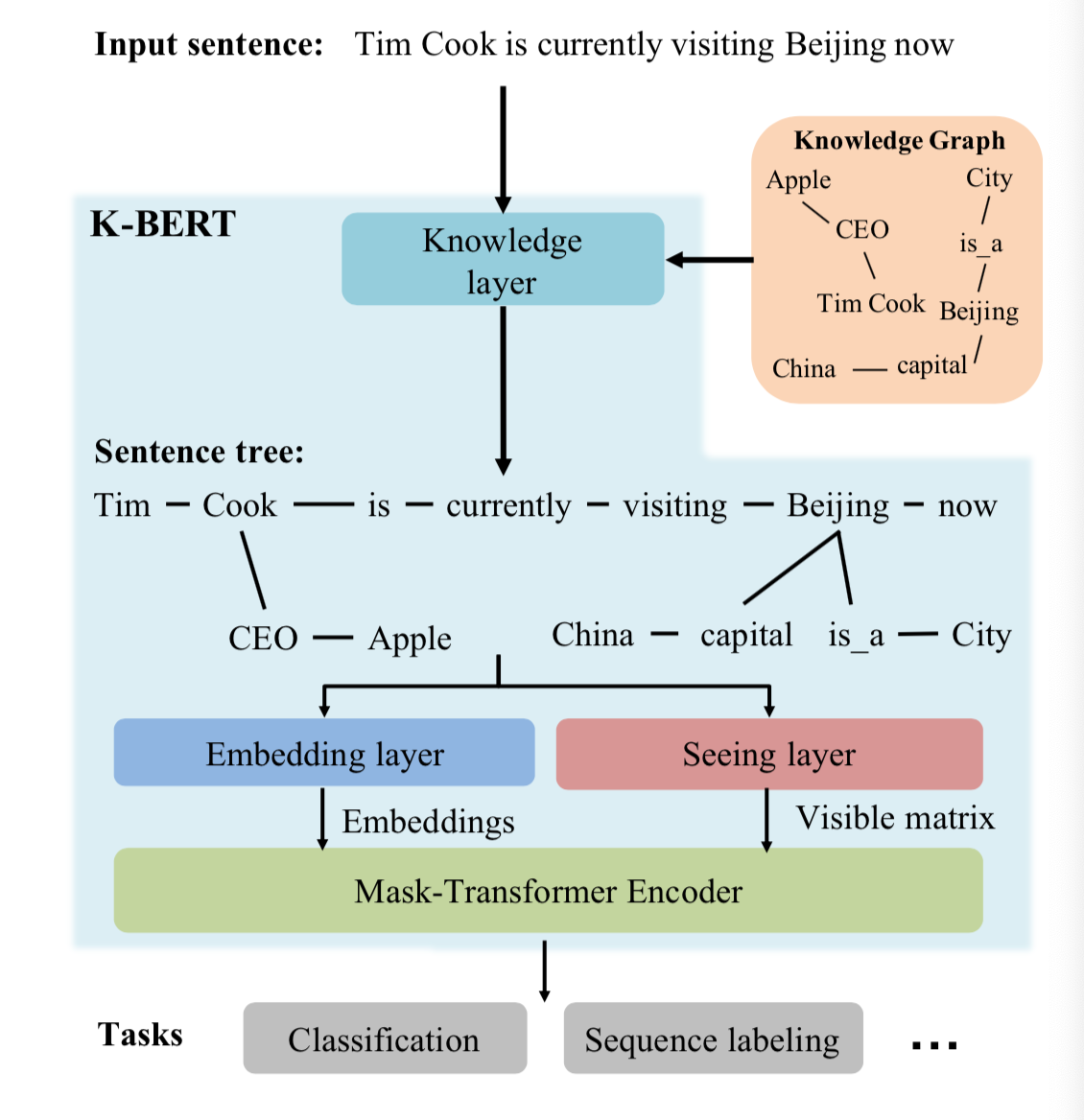
- 第一层: 知识层(Knowledge Layer)
- 当一个句子“Tim Cook is currently visiting Beijing now”输入时, 首先会经过一个知识层(Knowledge Layer), 知识层将知识图谱中关联到的三元组信息(Apple-CEO-Tim Cook, Beijing-capital-China等)注入到句子中, 形成一个富有背景知识的句子树(Sentence tree).
- 通过知识层, 一个句子序列被转换成了一个树结构或图结构, 其中包含了句子中原本没有的背景知识, 即我们知道“苹果的CEO现在在中国”.
- 知识层最主要的任务是输出一个句子树, 主要包含两个具体的步骤:
- 第一步: 知识查询(K-Query), 利用输入句子中所有的实体去查询知识图谱中相关的三元组. E = K_Query(s, K)
- 第二步: 知识注入(K-Inject), 将相关三元组集合E, 注入到句子中形成句子树. tree = K_Inject(s, E)
- 问题反思: 得到了句子树以后, 问题出现了. 传统的BERT模型, 只能处理序列结构的句子输入, 而图结构的句子树是无法直接输入到BERT模型中的. 如果强行把句子树平铺成序列输入模型, 必然造成结构信息的丢失. 在这里, K-BERT提出了一个很巧妙的解决办法, 那就是软位置(Soft-position)和可见矩阵(Visible Matrix).
K-BERT模型细节¶
- 第二层: 嵌入层(Embedding layer)
- 嵌入层最关键的概念就是软位置(Soft-position)
- 众所周知, 在BERT中将句子序列输入到模型之前, 会给句子序列中的每个token加上一个位置编码, 即token在句子中的位置次序编号, 例如“Tim(0) Cook(1) is(2) currently(3) visiting(4) Beijing(5) now(6)”. 如果没有位置编码, 那BERT模型是没有顺序信息的, 相当于一个词袋模型.
- 将句子树转换为嵌入表示和可见矩阵的过程如下图展示.
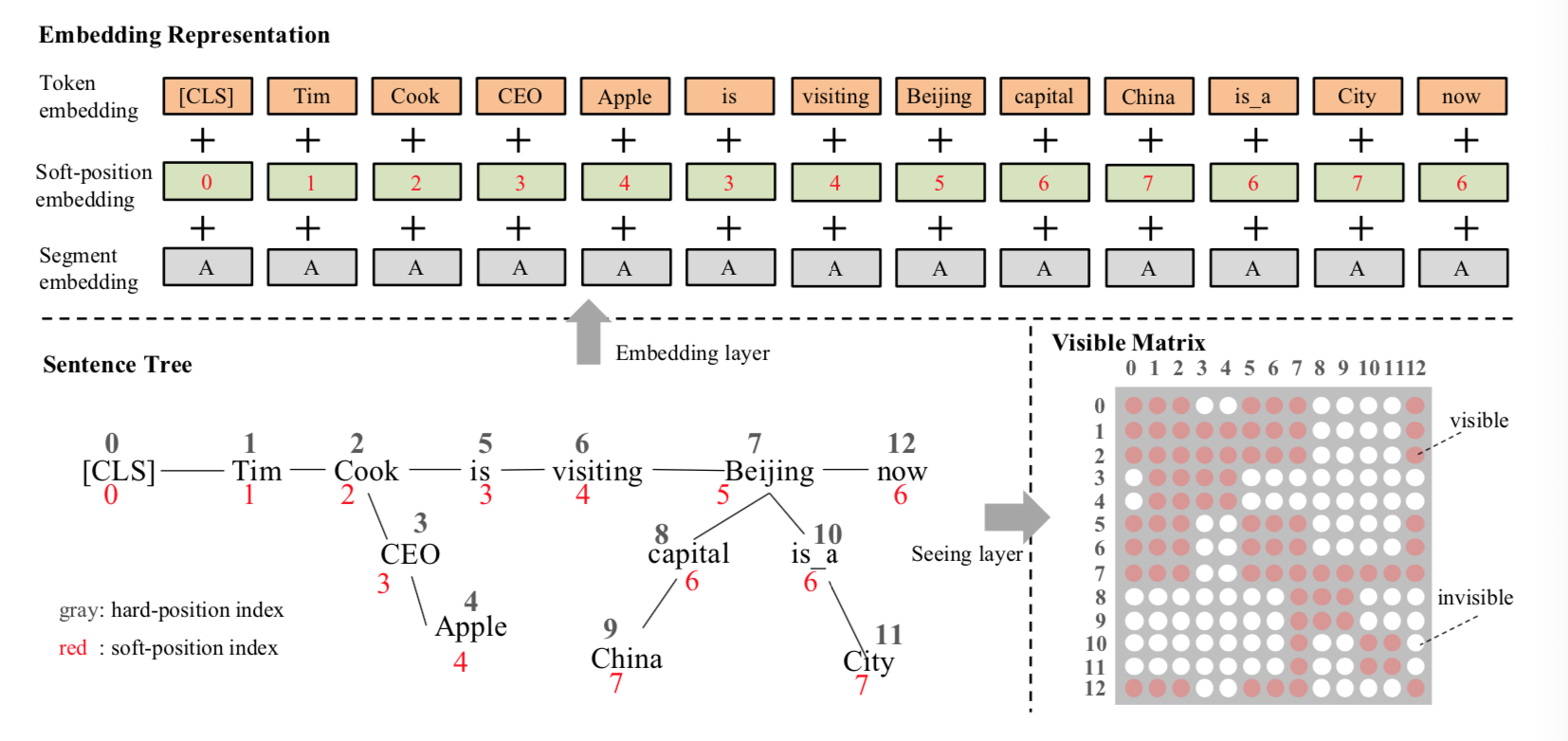
- 在句子树中, 红色的数字是软位置索引, 灰色的是硬位置索引.
- 1: 对于令牌嵌入, 将句子树中的令牌按其硬位置索引平铺成令牌嵌入序列.
- 2: 软位置索引与令牌嵌入一起作为位置嵌入.
- 3: 在分段嵌入中, 第一句中的所有标记都标记为“A”.
- 4: 在可见矩阵(Visual Matrix)中, 红色表示可见, 白色表示不可见. 例如, 第4行第9列的单元格是白色的, 表示“Apple(4)”看不到“China(9)”.
- 反思1: 嵌入层的功能是将语句树转换为可以馈送到掩码转换器中的嵌入表示. 与BERT相似, K-BERT的嵌入表示是由符号嵌入, 位置嵌入和段嵌入三部分组成, 不同之处在于K-BERT嵌入层的输入是句子树, 而不是符号序列. 因此如何在保留句子树结构信息的同时将句子树转换成序列是K-BERT的关键.
- 反思2: 符号嵌入与BERT基本一致, 不同之处在于语句树中的符号在嵌入操作之前需要重新排列. 在重新排列策略中, 分支中的符号被插入到相应节点, 而后续的符号则向后移动. 经此操作后句子变得不可读, 丢失了正确的结构信息, 但该问题可以通过软位置加可视矩阵来解决.
- 反思3: BERT输入句子的所有结构信息都包含在位置嵌入中, 可以将缺失的结构信息重新添加到不可读的重新排列的句子中, 但句子位置信息会有所改变. 要解决这个问题, 需要给句子树重新设置位置标号. 但在设置位置编号时又会发生实际没有联系的词汇, 因具有相同的软位置标号而出现联系, 导致句子意思再次发生改变. 这个问题的解决方案是使用掩码-自我注意机制.
-
第三层: 视图层(Seeing layer)
-
详细解释一下上图:
- 1: 在 K-BERT 中, 首先会将句子树平铺,例如图 2 中的句子树平铺以后是“[CLS] Tim Cook CEO Apple is currently visiting Beijing capital China is_a City now”.
- 2: 显然, 平铺以后的句子是杂乱不易读的, K-BERT 通过软位置编码恢复句子树的顺序信息, 即“CLS Tim(1) Cook(2) CEO(3) Apple(4) is(3) visiting(4) Beijing(5) capital(6) China(7) is_a(6) City(7) now(6)”, 可以看到“CEO(3)”和“is(3)”的位置编码都3, 因为它们都是跟在“Cook(2)”之后.
- 3: 只用软位置还是不够的, 因为会让模型误认为Apple (4)是跟在is (3)之后, 这是错误的. K-BERT 中最大的亮点在于Mask-Transformer, 其中使用了可见矩阵(Visible Matrix)将图或树结构中的结构信息引入到模型中.
- 4: BERT中Self-attention, 一个词的词嵌入是来源于其上下文. Mask-Transformer核心思想就是让一个词的词嵌入只来源于其同一个枝干的上下文, 而不同枝干的词之间相互不影响. 这就要通过可见矩阵来实现, 图中的句子树对应的可见矩阵如右侧子图所示, 其中一共有13个token, 所以是一个13*13的矩阵, 红色表示对应位置的两个token相互可见, 白色表示相互不可见.
-
第四层: 掩码层(Mask-Transformer Encoder)
-
有了可见矩阵以后, 可见矩阵该如何使用呢? 其实很简单, 就是Mask-Transformer. 对于一个可见矩阵M, 相互可见的红色点取值为0, 相互不可见的白色取值为负无穷, 然后把M加到计算self-attention的softmax函数里就好, 即如下公式:

- 结论: 以上公式只是对BERT里的self-attention做简单的修改, 多加了一个M, 其余并无差别. 如果两个字之间相互不可见, 它们之间的影响系数S[i,j]就会是0, 也就使这两个词的隐藏状态h之间没有任何影响. 这样, 就把句子树中的结构信息输入给BERT了.
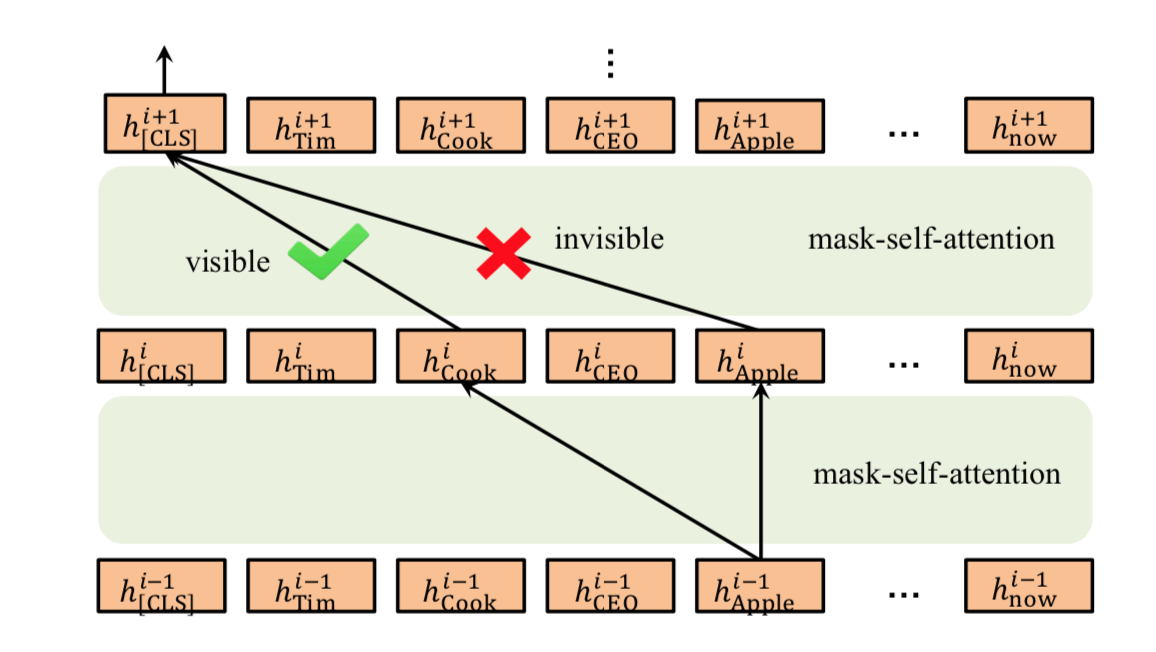
- 掩码转换器的插图: 它是多个掩码自我注意块的堆栈. [Apple]只能通过[Cook]间接作用于[CLS], 降低了知识噪声的影响!!!
K-BERT模型的优化点¶
- 除了软位置和可见矩阵, K-BERT模型其余结构均与BERT保持一致, 这就给K-BERT带来了一个很好的特性-兼容BERT类的模型参数. K-BERT可以直接加载Google BERT, Baidu ERNIE, Facebook RoBERTa等市面上公开的已预训练好的BERT类模型, 无需自行再次预训练, 给使用者节约了很大一笔计算资源. 这也是K-BERT模型所带来的的一大启发, 模型架构的一大亮点!!!
- K-BERT在开放域的多项任务中展现了明显优于BERT的水平.
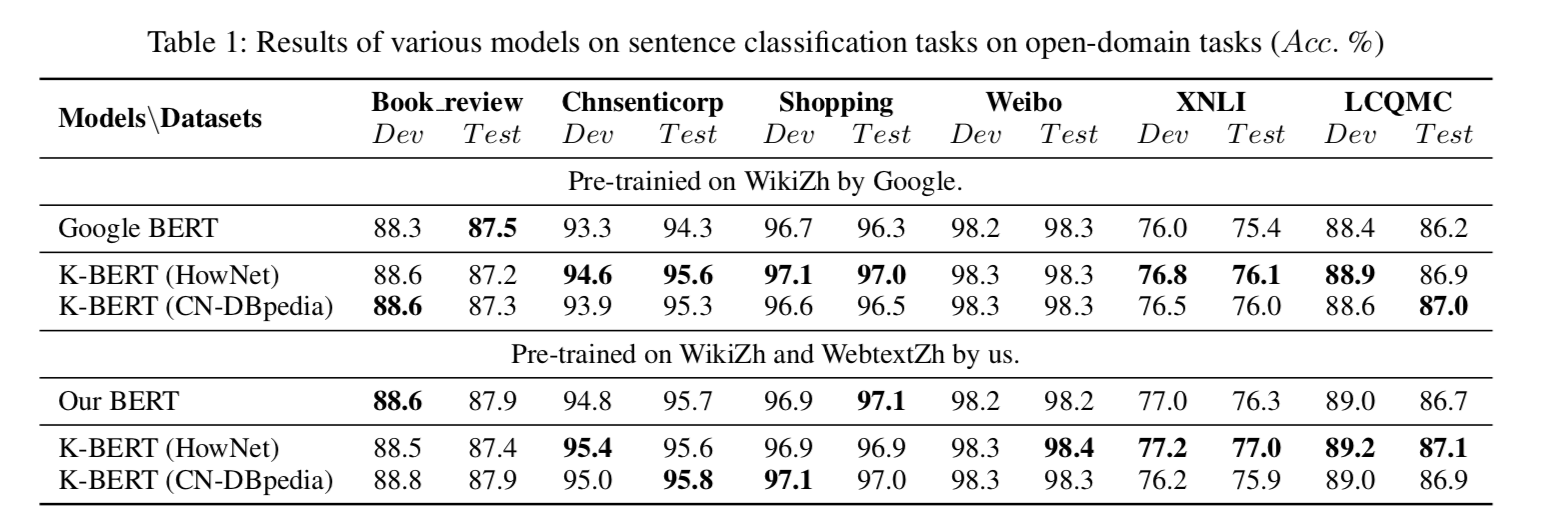
- K-BERT在著名的QA问题, NER问题等困难任务中也展现了更优的水平.
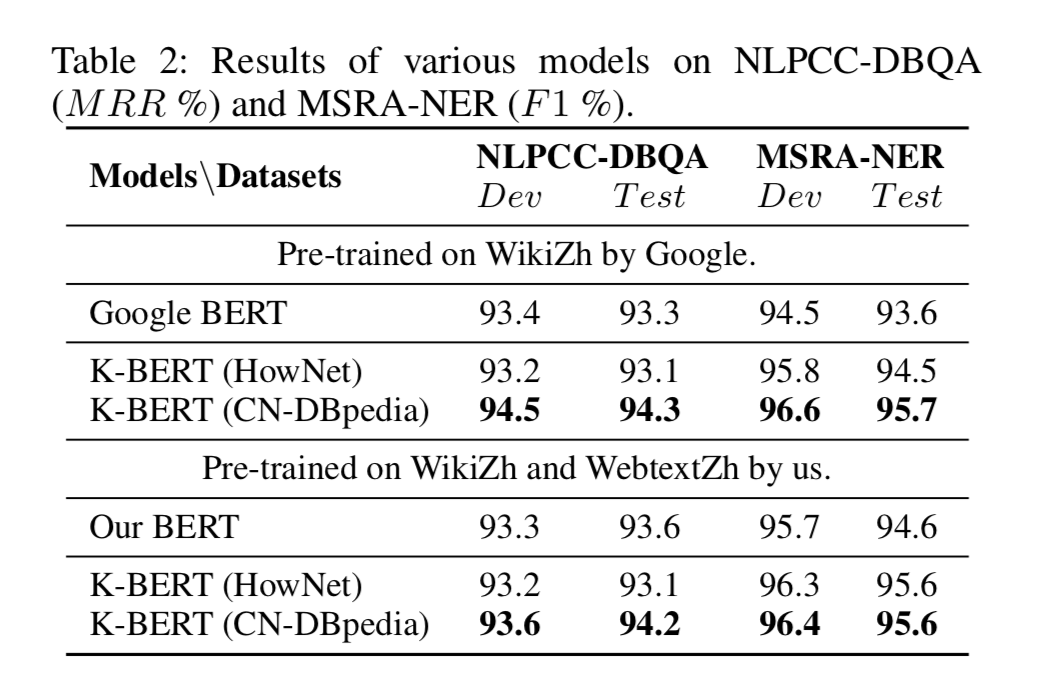
KG-BERT模型¶
学习目标¶
- 掌握KG-BERT模型的架构.
- 掌握KG-BERT模型的优化点.
KG-BERT模型的架构¶
-
在先前的KGE方法中, 虽然它们能学到独特的实体关系表示, 但是却忽略了上下文. 句法和语义信息在大规模文本数据中没有得到很好的利用, 它们仅仅使用了实体描述, 关系提及或者实体共现.
-
因为BERT在NLP中作为PLM取得的成果非常亮眼, 所以作者希望将它迁移到知识图谱补全任务中, 测试其在KGC中的性能. BERT是针对自然语言进行处理的, 作者简单的将实体和关系描述放入BERT, 使BERT能够获取KGC的能力, 称之为KG-BERT. 这是第一项使用PLM对三元组进行建模的研究.
-
模型源于论文<< KG-BERT: BERT for Knowledge Graph Completion >>, 针对要解决的问题是知识图谱补全的领域. 发表于2019年.
- 既然BERT是基于自然语言的, 那么很容易就想到用实体和关系的描述或者它们的名字放入BERT, 然后获得通过某种训练方式得到三元组的表示. 作者设计了两种训练方式的KG-BERT, 这样能使它被运用到不同的知识图谱补全任务当中.
- 第一种方式: KG-BERT(a)
- 完全沿用了BERT的方法, 将实体, 关系描述或名字全部放入BERT中, 并用[CLS]处的隐态输出 来预测三元组是否正确, 该方式与BERT中的NSP任务完全一致. 第一种方式是针对三元组建模的.
- 在不同实体和关系之间用[SEP] 进行分隔, 并且每个Token的描述分别由Token本身的Embedding, Segment Embedding, Position Embedding组成. Segment Embedding因元素类型不同而不同, 头实体和尾实体都使用e_A作为Segment Embedding, 而关系采用e_B作为Segment Embedding.
- 最后把[CLS]处的隐藏层张量用来计算三元组的分类, 总体架构图如下:
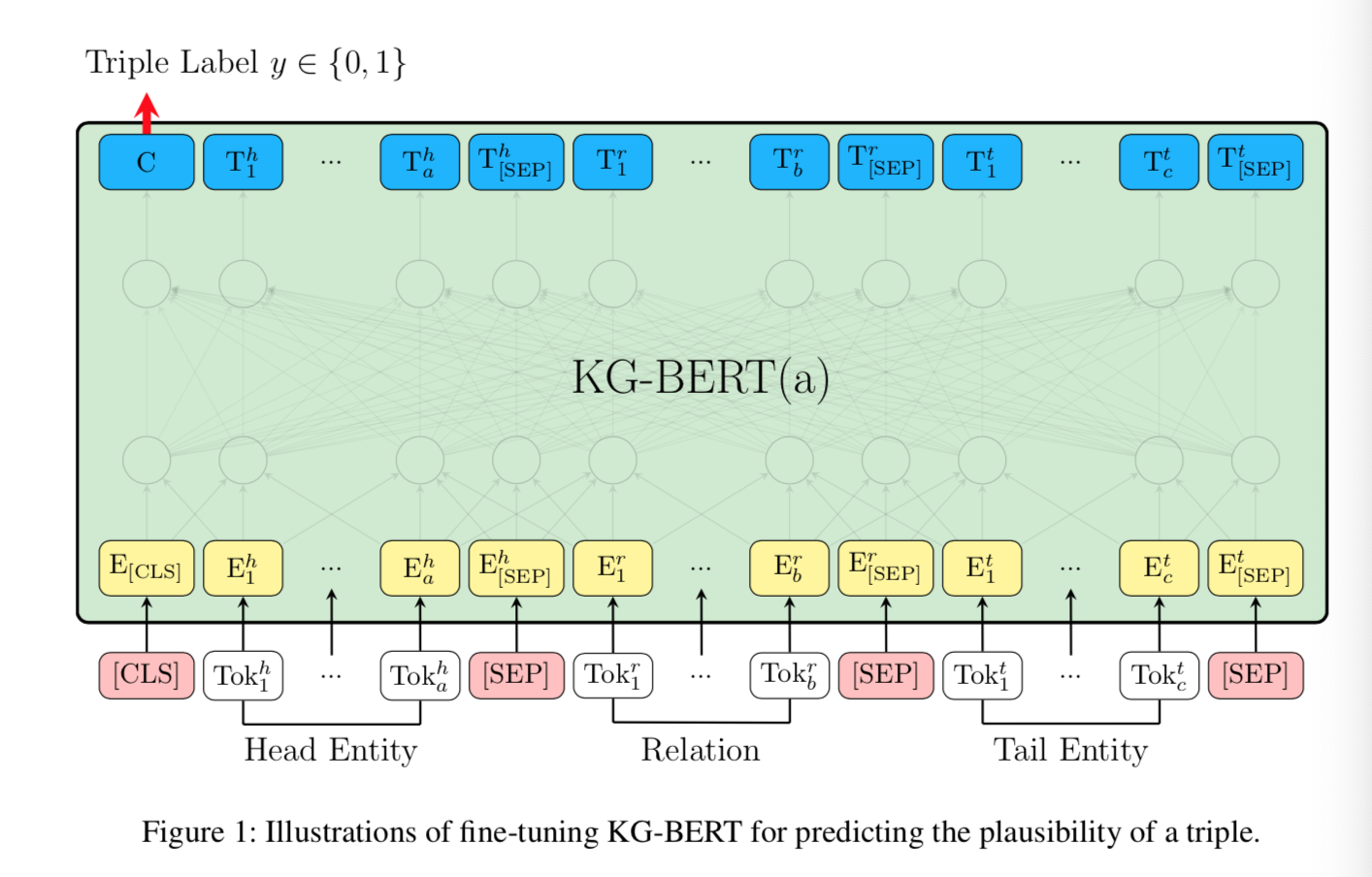
- 对于KG-BERT(a)方式, 优化用的损失函数为BCE, 负样本仍然来源于负采样, 仅替换头实体和尾实体得来:

- 第二种方式: KG-BERT(b)
- 作者只使用两个实体的描述来预测它们之间的关系. 在实验中, 作者发现这种结构在预测关系时效果要优于KG-BERT(a).
- KG-BERT(b)采用[CLS]处的隐藏层张量输出, 后接一个分类矩阵来预测两实体之间的关系, 最后的多分类函数也从sigmiod换成了softmax.
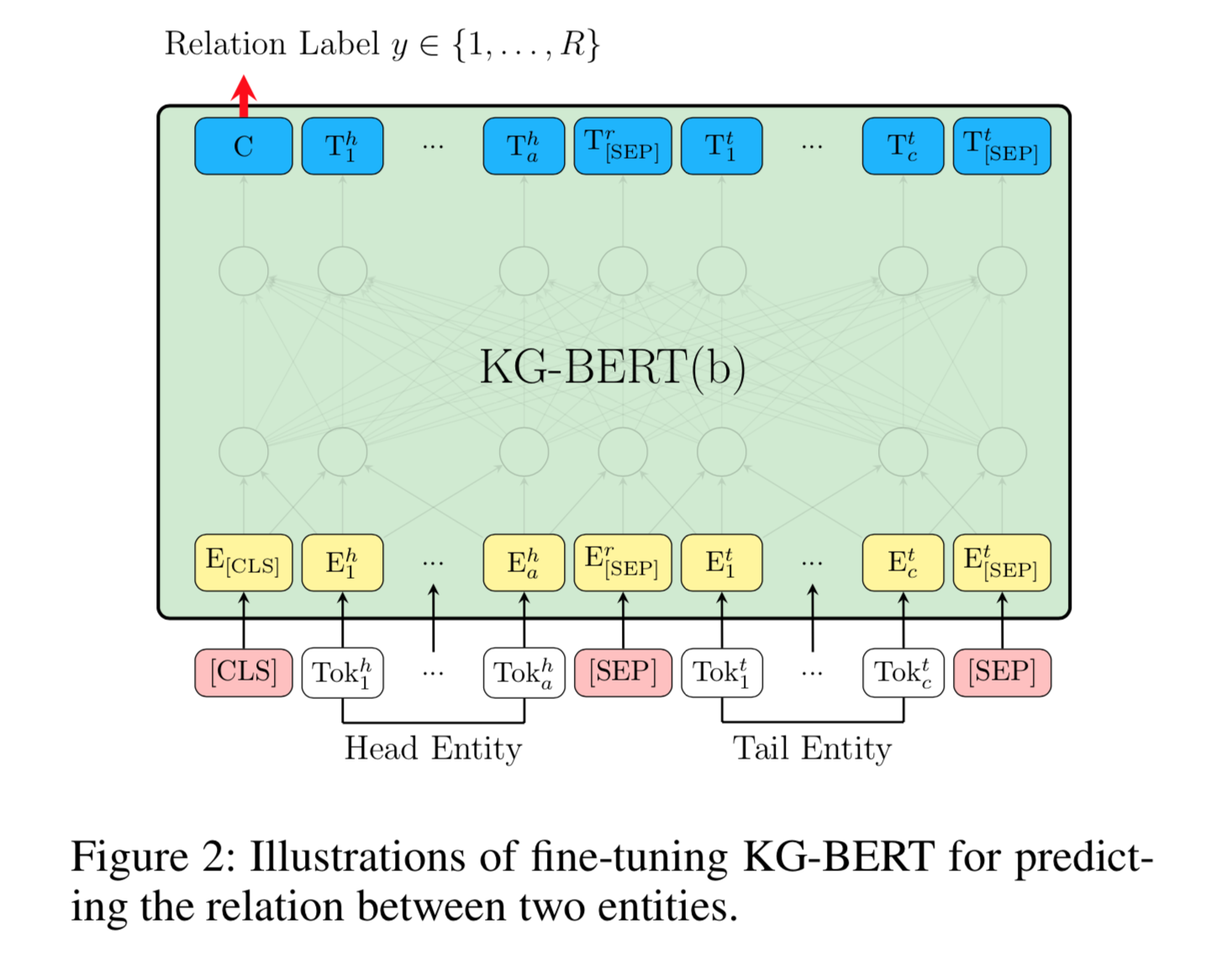
- 对于KG-BERT(a)方式, 优化用的损失函数为Cross-Entropy, 负样本仍然来源于负采样, 只是对正例三元组的关系进行替换即可.
KG-BERT模型的优化点¶
-
在实验中, 作者希望探究KG-BERT的下述能力:
- 模型能不能判断没见过的三元组的正确与否? (Triple Classification, 对应KG-BERT(a))
- 模型能不能根据给出的单个实体和关系描述预测出另一个实体? (Link Prediction)
- 模型能不能预测两个实体之间的关系? (Relation Prediction, 对应KG-BERT(b))
-
作者使用BERT-BASE初始化权重, 因为BASE比LARGE版本所受超参影响更小, 可选择的超参也很少. KG-BERT模型主要为了解决Knowledge Graph Compeltion Tasks.
- Triple Classification: 对于三元组分类任务, 作者做了很多对比实验, 发现KG-BERT效果非常明显.
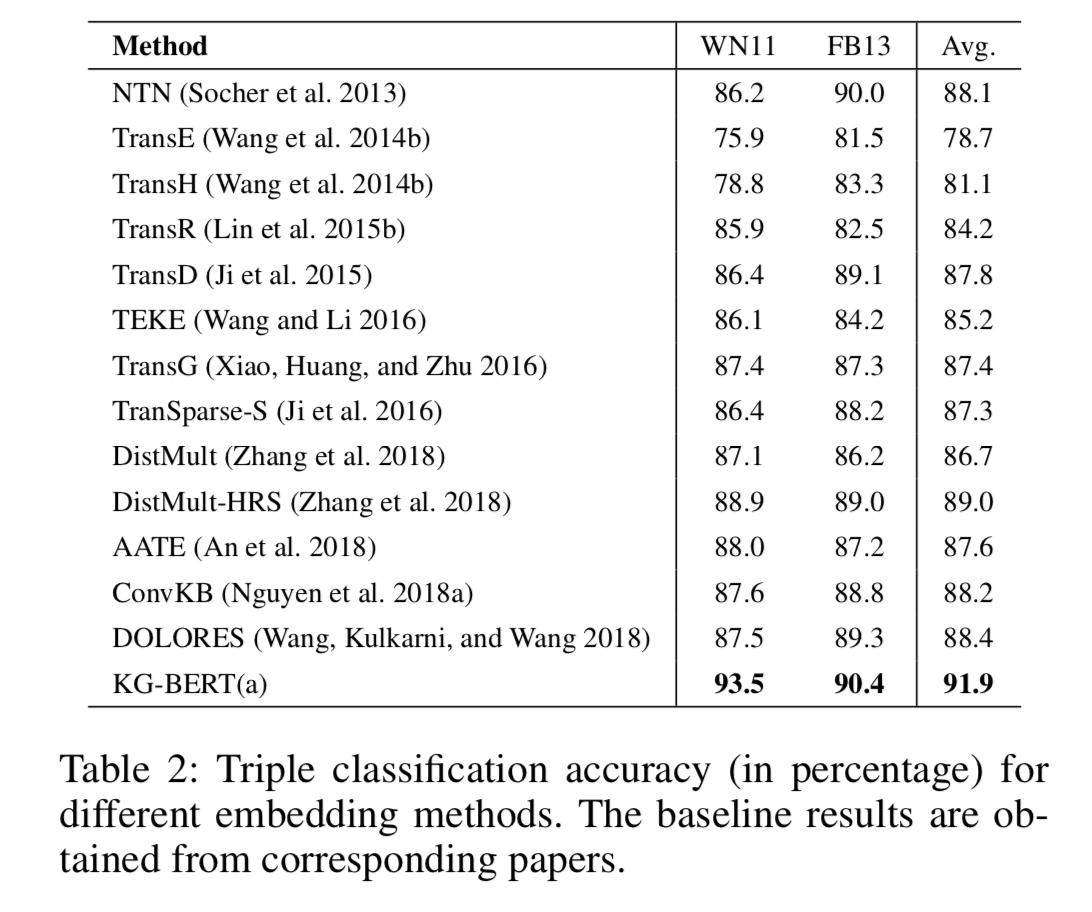
- 上述优秀表现, 论文作者将其总结如下:
- 输入中含有实体和关系的单词序列(使用了文本描述).
- 三元组分类与BERT训练时的NSP任务类似.
- Token Vector结合了上下文, 在不同的三元组中描述往往是不同的, 因此不同三元组中的相同元素能获得不同表示.
- Self Attention很强大.
- 论文作者绘制了测试集准确率随着训练集数据量的提升的变化曲线:
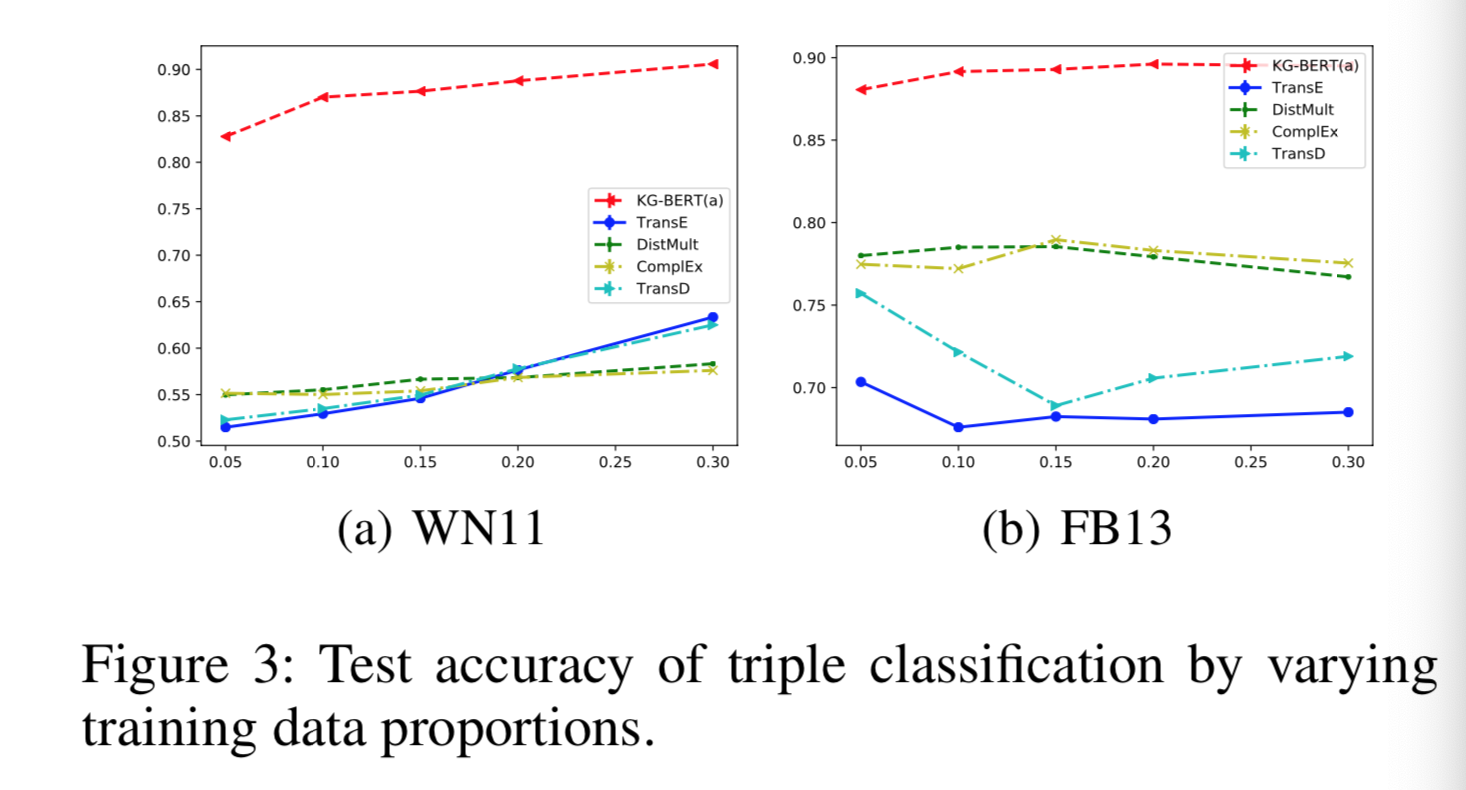
- 结论: KG-BERT从一开始就优于其他模型, 得益于BERT强大的特征提取能力!
- 论文中对于Link Prediction任务, 还有Relation Prediction任务都做了对比实验, 发现KG-BERT都有优秀的表现!