5.4 T5模型介绍
T5模型¶
学习目标¶
- 掌握T5模型的架构.
- 掌握T5模型的优化点.
- 掌握T5模型的应用.
T5模型架构¶
-
T5模型也是Google出品的精品预训练模型.
-
<< Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer >>.
- 简称Transfer Text-To-Text Transformer, 所以称呼T5.
-
T5模型的内部基本采用了Transformer的结构, 但是核心思想在于将所有的NLP任务"大一统到seq2seq架构"中. 也就是说, 在T5模型中作者进行了多种优化方案的尝试, 各种对比实验, 消融实验, 得到一个最优的框架.
-
T5本身没有什么算法上的亮点, 也没有模型结构上的巨大创新, 它最重要的作用是为NLP预训练模型提供了一个通用的框架, 为解决方案提供了一种通用思路, 那就是"万物皆可seq2seq"!
T5训练和应用流程¶
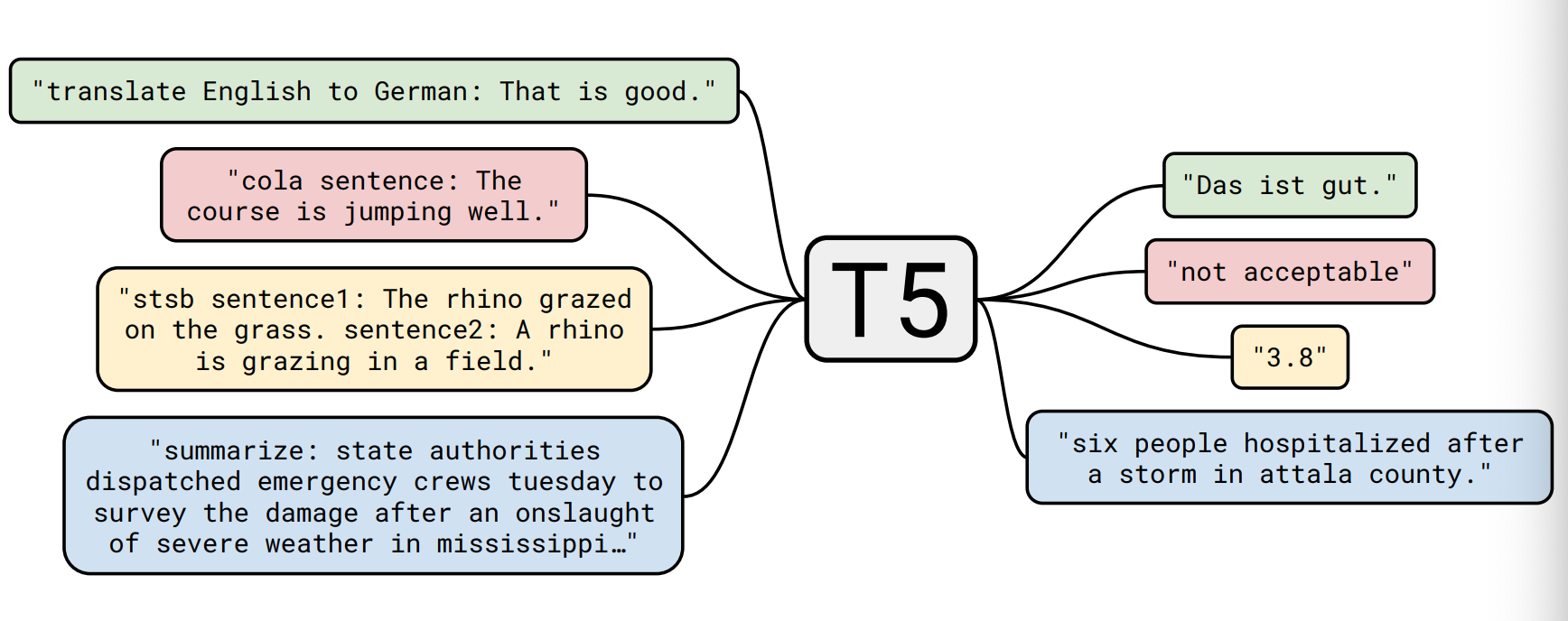
- T5模型在训练的时候所采用的的套路和应用时是一致的, 并且和下游任务一一对应, 非常清晰易懂.
- 比如当前任务是进行英德翻译, 只需要将训练数据集的输入部分前面加上"translate English to German"就行了. 假设我要把英文文本"That is good"翻译成德文, 只要把输入数据转换成"translate English to German: That is good", 直接输入模型中, 模型的输出就是翻译后的德文"Das ist gut".
- 再比如要进行情感分析(舆情监控)任务, 只需要将训练数据集的输入部分前面加上"sentiment"就行了. 假设我当前要对文本"This movie is terrible!"进行情感分析, 只要把输入数据转换成"sentiment: This movie is terrible!", 直接输入模型中, 模型的输出就是分析后的结果"negative".
- 比如我要进行STS-B(文本语义相似度任务), 原始的任务可以认为是一个回归任务, 因为需要得到一个连续值. 但是T5模型以每0.2为一个间隔, 从1分到5分之间分成21个离散值, 转换成了21分类任务. 比如架构图中的那个3.8其实并不是"浮点数值", 而是"字符串文本", 本质上是一个分类标签!
- T5模型的训练数据集
- T5模型的数据集是从Common Crawl (一个公开的网页存档数据集, 每个月大概抓取20TB的互联网文本数据)中清理出了750GB的训练数据, 取名为"Colossal Clean Crawled Corpus"(超大型干净的爬虫数据集), 简称"C4"! (不得不佩服谷歌起名的口味!)
- 关于C4数据集的清洗操作:
- 1: 只保留结尾是正常符号的行.
- 2: 删除任何包含脏词汇的页面.
- 3: 包含JavaScript词的行全部删除.
- 4: 包含编程语言中常用的大括号的页面全部删除.
- 5: 包含任何排版测试的页面全部删除.
- 6: 连续三句话重复出现的情况下, 只保留一行.
- T5预训练策略的选择
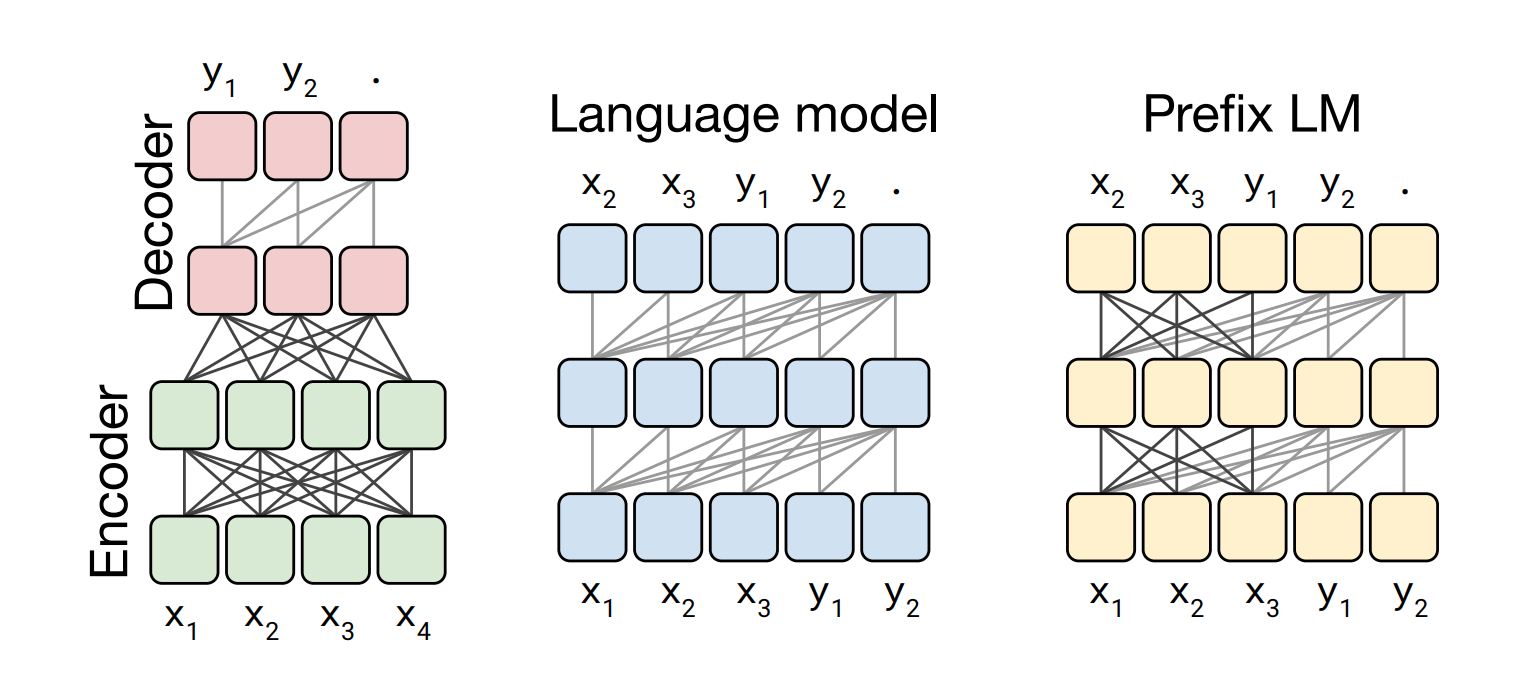
- 关于预训练策略, 主流架构主要有3种:
- 第1种: Encoder-Decoder, 即大家熟悉的seq2seq架构, 分为编码器和解码器两部分. 对于Encoder可以看到前面, 也可以看到后面. 结果作为输入传递给Decoder. 对于Decoder只能看到前面的信息. BERT可以看做只有Encoder的模型.
- 第2种: 相当于只有Decoder部分, 只能看到前面的信息, 典型代表就是GPT2模型.
- 第3种: Prefix LM, 前缀模型, 可以看成是Encoder和Decoder的融合体, 一部分等效于Encoder可以看到前面, 也可以看到后面, 另一部分等效于Decoder只能看到前面的信息.
- 经过作者大量的对比实验后, 发现第1种Encoder-Decoder架构效果最优, 因此T5模型中采用了第1种架构.
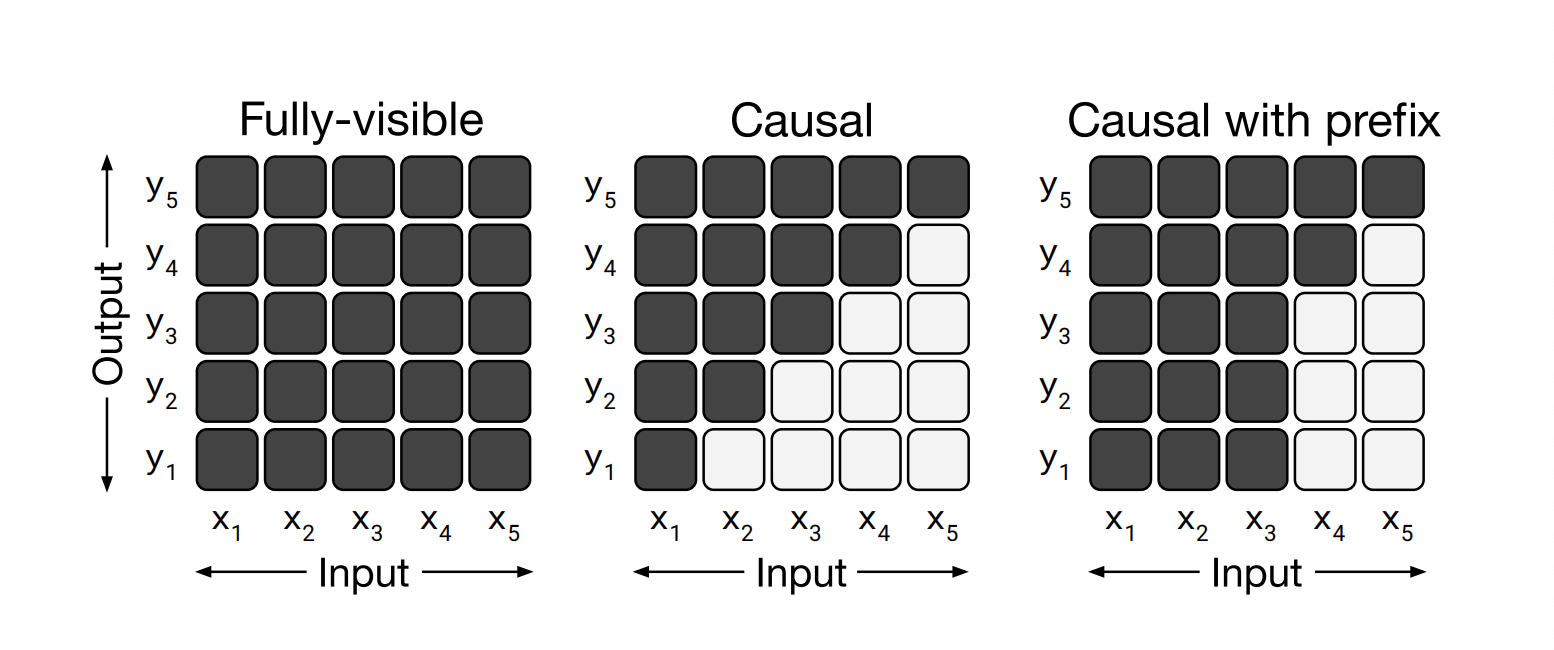
- 其实上图中所展示的3种架构策略, 本质上内部结构都是基于Transformer, 只是MASK机制不同:
-
T5文本MASK策略的选择
-
这里面有宏观角度和微观角度两方面:
- 宏观角度: 可以理解为自监督训练方法, 总共有3种策略可选.
- 1: GPT-style, 生成式语言模型的方式, 类似于GPT2, 从左到右预测.
- 2: BERT-style, MLM的方式, 类似于BERT将token遮掩掉, 然后再还原出来.
- 3: Deshuffling-style, 将文本顺序打乱, 然后再还原出来.
- 微观角度: 可以理解为具体对什么粒度的文本进行MASK操作, 总共有3种策略可选.
- 1: token mask法, 即直接将单个token替换成[MASK].
- 2: replace span法, 可以将相邻的若干个token合并成一个[MASK].
- 3: drop法, 没有替换操作, 直接将随选定的token删除掉.
- 宏观角度: 可以理解为自监督训练方法, 总共有3种策略可选.

- 经过T5作者大量的试验, 发现宏观监督的BERT-style最好, 微观角度的replace span最好, 因此在T5模型中共同采用这两种策略.
-
T5预训练百分比策略的选择
-
按照前面选定的策略, 最后一步就是确定一下训练语料中多大比例的文本参与这种MASK策略了. T5作者也进行了大量的对比实验如下:

- 最后T5的作者发现15%的MASK比例最优, 同时span=3这个值最优. 再次不得不佩服BERT的作者Devlin这个老司机的直觉真厉害!
- 关于T5的几个版本效果的对比.
- Small: Encoder和Decoder都只有6层, 隐藏层的维度取512, head=8, 参数总量60 million.
- Base: Encoder和Decoder都采用BERT-base的参数, 参数总量220 million.
- Large: Encoder和Decoder都采用BERT-large的参数, 但层数保留12, 参数总量770 million.
- 3B: 在BERT-large的参数基础上, 层数采用24层, 参数总量3 Billion.
- 11B: 在3B参数基础上, FNN和head选取的更大, 参数总量11 Billion.
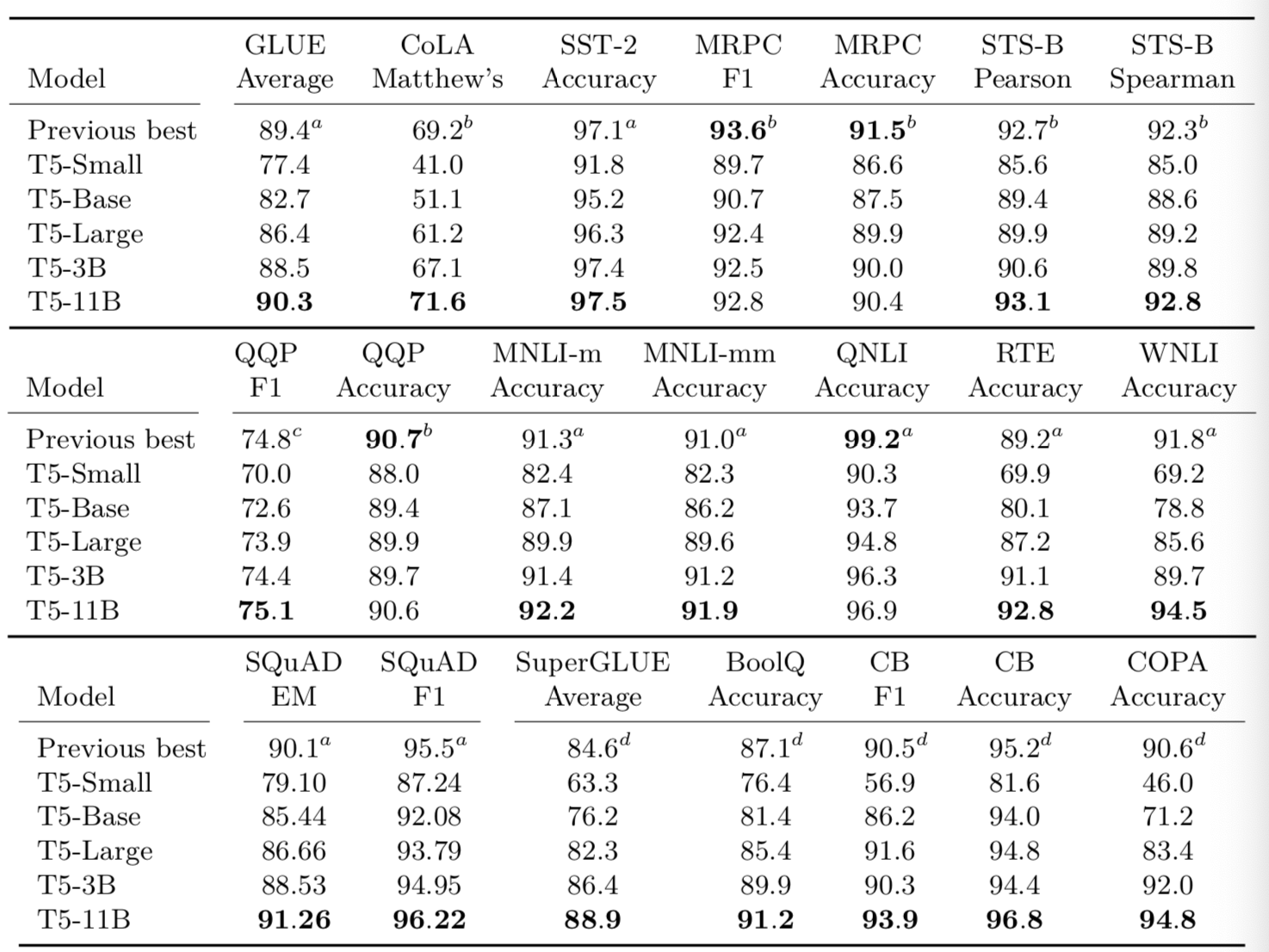
- 结论: 相比较之前的RoBERTa和AlBERT的SOTA基线, T5模型的Small, Base, Large并没有什么突出表现, 几乎在所有的基准测试中全部处于下风. 到了3B版本才有接近于Previous Best的表现. 直到继续暴力拉升到11B的参数版本, 才显示出T5模型的优势. 所以"Bigger is better?"真的是疑问句吗? 值得每一个AI科学家, AI工程师反思!!!
T5模型的应用¶
-
关于T5模型的具体应用, 包含文本分类, 机器翻译, 生成式对话, 摘要任务, 阅读理解等等.
-
关于常见的预训练模型, 可以直接到https://huggingface.co/models网站下载, 非常方便.
小节总结¶
- 本小节学习了T5模型的架构, 总结来看即如下5点:
- 1: 架构上采用了Encoder-Decoder模型.
- 2: 宏观上MASK策略采用了BERT-style的策略.
- 3: 微观上MASK策略采用replace span的段式MASK.
- 4: 宏观上进行MASK的比例采用15%.
- 5: 微观上进行MASK的段长span等于3.