5.2 AlBERT模型介绍
AlBERT模型¶
学习目标¶
- 掌握AlBERT模型的架构.
- 掌握AlBERT模型的优化点.
AlBERT模型架构¶
- 经典Transformer的架构图如下:
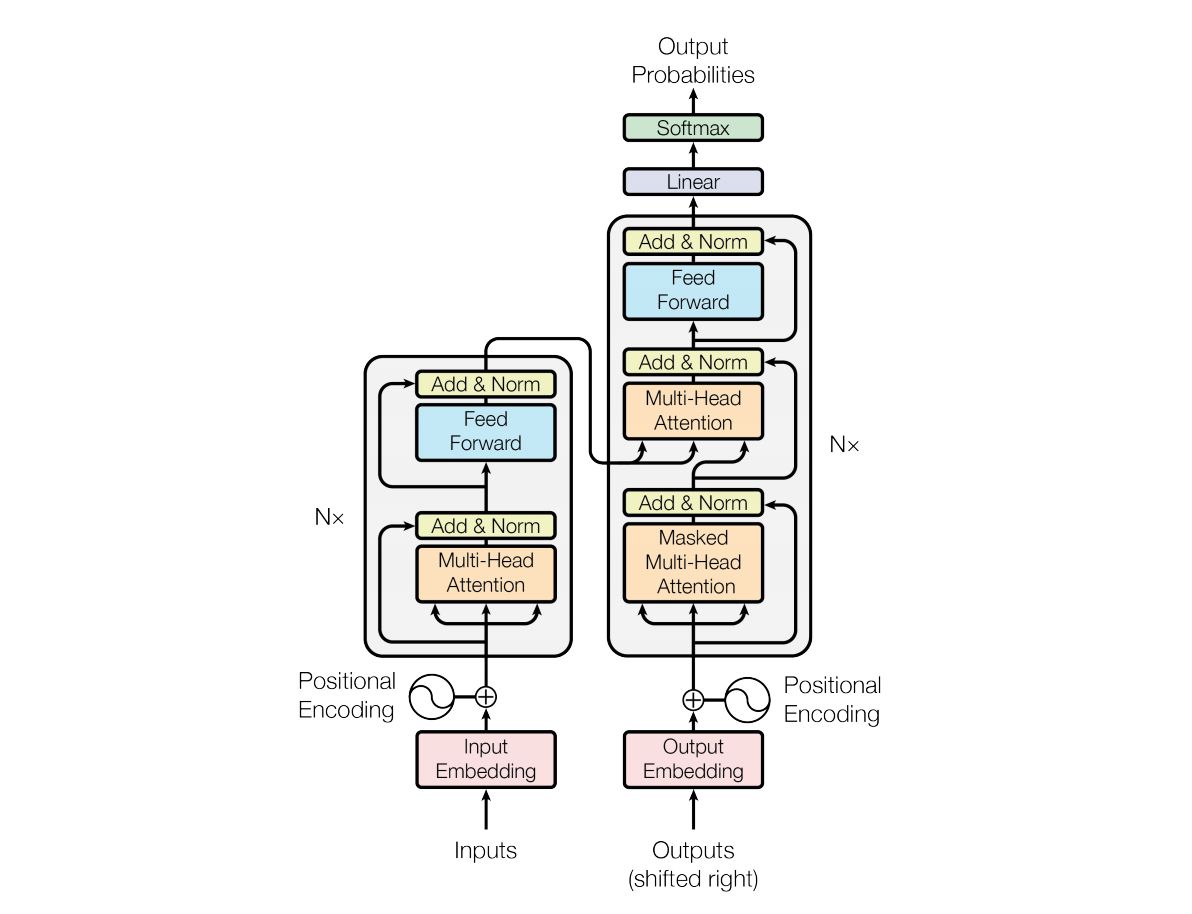
- 左半部编码器就是BERT的前身, 右半部解码器就是GPT的前身.
-
AlBERT模型发布于ICLR 2020会议, 是基于BERT模型的重要改进版本. 是谷歌研究院和芝加哥大学共同发布的研究成果.
-
论文全称<< A Lite BERT For Self-Supervised Learning Of Language Representations >>.
- 在本篇论文中, 首先对比了过去几年预训练模型的主流操作思路.
- 第一: 大规模的语料.
- 第二: 更深的网络, 更多的参数.
- 第三: 多任务训练.
- 关于词嵌入层, 对比了BERT和AlBERT对应于输入和输出的定量距离如下:
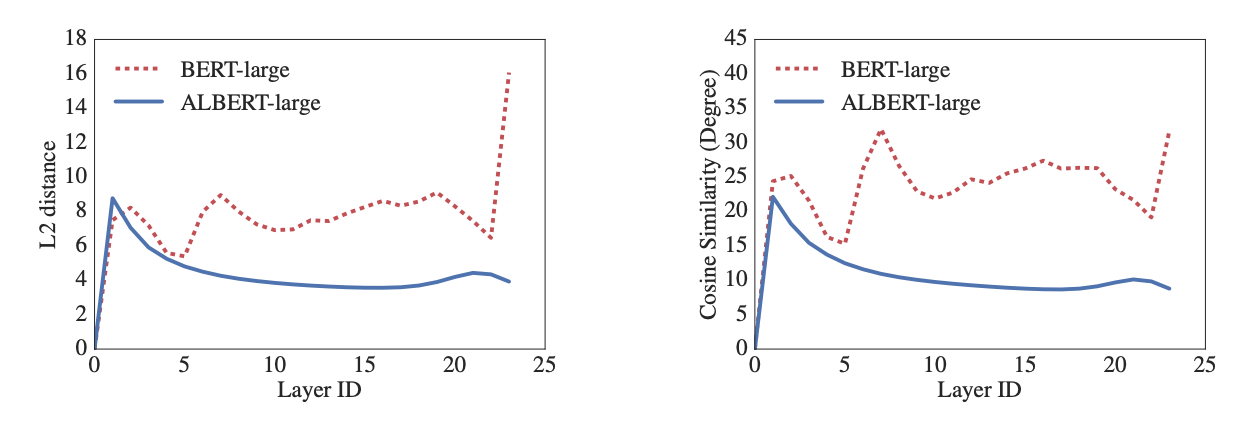
- 结论: 首先看原始论文中的论述, We observe that the transitions from layer to layer are much smoother for ALBERT than for BERT. These results show that weight-sharing has an effect on stabilizing network parameters. 可以看出BERT模型中词嵌入的L2距离和余弦相似度是震荡的, 而AlBERT显示出了更好的网络性能, 从一层到另一层的转换要平滑的多. 相当于AlBERT模型有效提升了神经网络参数的鲁棒性.
- 下图展示了主流的BERT和AlBERT的模型参数对比:
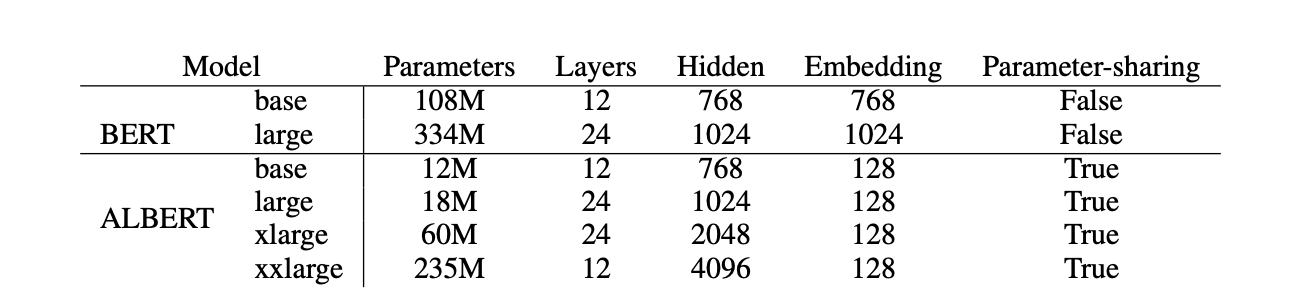
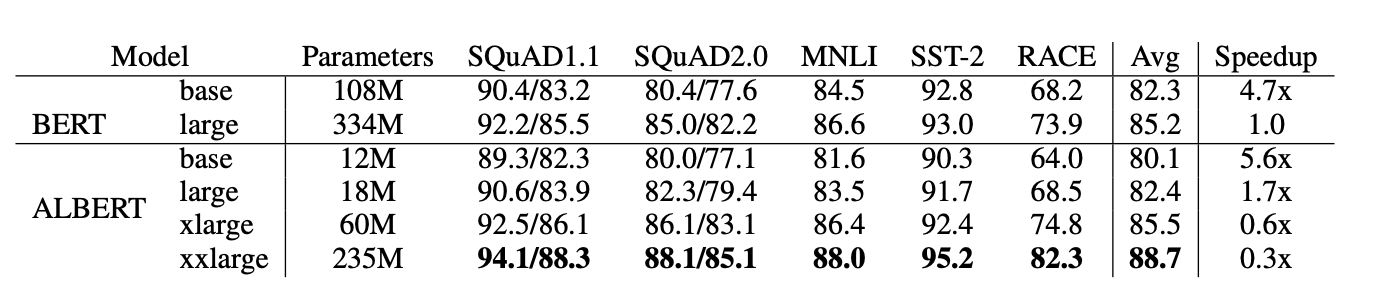
- 新模型的提出, 一个最重要的结论就是要在主流测试中超过老模型, 论文中展示了AlBERT在主流任务中的测试结果如下:
AlBERT模型的优化点¶
- 相比较于BERT模型, AlBERT的出发点即是希望降低预训练的难度, 同时提升模型关键能力. 主要引入了5大优化.
- 第一: 词嵌入参数的因式分解.
- 第二: 隐藏层之间的参数共享.
- 第三: 去掉NSP, 增加SOP预训练任务.
- 第四: 去掉dropout操作.
- 第五: MLM任务的优化.
-
第一: 词嵌入参数的因式分解.
-
AlBERT的作者认为, 词向量只记录了少量的词汇本身的信息, 更多的语义信息和句法信息包含在隐藏层中. 因此词嵌入的维度不一定非要和隐藏层的维度一致.
- 具体做法就是通过因式分解来降低嵌入矩阵的参数:
- BERT: embedding_dim * vocab_size = hidden_size * vocab_size, 其中embedding_dim=768, vocab_size大约为30000左右的级别, 大约等于30000 * 768 = 23040000(2300万).
- AlBERT: vocab_size * project + project * hidden_size, 其中project是因式分解的中间映射层维度, 一般取128, 参数总量大约等于30000 * 128 + 128 * 768 = 482304(48万).
-
第二: 隐藏层之间的参数共享.
-
在BERT模型中, 无论是12层的base, 还是24层的large模型, 其中每一个Encoder Block都拥有独立的参数模块, 包含多头注意力子层, 前馈全连接层. 非常重要的一点是, 这些层之间的参数都是独立的, 随着训练的进行都不一样了!
-
那么为了减少模型的参数量, 一个很直观的做法便是让这些层之间的参数共享, 本质上只有一套Encoder Block的参数!
-
在AlBERT模型中, 所有的多头注意力子层, 全连接层的参数都是分别共享的, 通过这样的方式, AlBERT属于Block的参数量在BERT的基础上, 分别下降到原来的1/12, 1/24.
-
第三: 去掉NSP, 增加SOP预训练任务.
-
BERT模型的成功很大程度上取决于两点, 一个是基础架构采用Transformer, 另一个就是精心设计的两大预训练任务, MLM和NSP. 但是BERT提出后不久, 便有研究人员对NSP任务提出质疑, 我们也可以反思一下NSP任务有什么问题?
-
在AlBERT模型中, 直接舍弃掉了NSP任务, 新提出了SOP任务(Sentence Order Prediction), 即两句话的顺序预测, 文本中正常语序的先后两句话[A, B]作为正样本, 则[B, A]作为负样本.
-
增加了SOP预训练任务后, 使得AlBERT拥有了更强大的语义理解能力和语序关系的预测能力.
-
第四: 去掉dropout操作.
-
原始论文中提到, 在AlBERT训练达到100万个batch_size时, 模型依然没有过拟合, 作者基于这个试验结果直接去掉了Dropout操作, 竟然意外的发现AlBERT对下游任务的效果有了进一步的提升. 这是NLP领域第一次发现dropout对大规模预训练模型会造成负面影响, 也使得AlBERT v2.0版本成为第一个不使用dropout操作而获得优异表现的主流预训练模型
- 第五: MLM任务的优化.
- segments-pair的优化:
- BERT为了加速训练, 前90%的steps使用了长度为128个token的短句子, 后10%的steps才使用长度为512个token的长句子.
- AlBERT在90%的steps中使用了长度为512个token的长句子, 更长的句子可以提供更多上下文信息, 可以显著提升模型的能力.
- Masked-Ngram-LM的优化:
- BERT的MLM目标是随机mask掉15%的token来进行预测, 其中的token早已分好, 一个个算.
- AlBERT预测的是Ngram片段, 每个片段长度为n (n=1,2,3), 每个Ngram片段的概率按照公式分别计算即可. 比如1-gram, 2-gram, 3-gram的概率分别为6/11, 3/11, 2/11.
- segments-pair的优化:
- AlBERT系列中包含一个albert-tiny模型, 隐藏层仅有4层, 参数量1.8M, 非常轻巧. 相比较BERT, 其训练和推理速度提升约10倍, 但精度基本保留, 语义相似度数据集LCQMC测试集达到85.4%, 相比于bert-base仅下降1.5%, 非常优秀.
- 关于常见的预训练模型, 可以直接到https://huggingface.co/models网站下载, 非常方便.
小节总结¶
- 本小节学习了AlBERT模型的架构和优化点.
- 主体网络结构采用和BERT一致的结构.
- 词嵌入部分采用了因式分解来降低参数量.
- 每一层的参数采用了参数共享的机制, 极大的降低了参数量.
- 去除掉BERT中的NSP任务, 新增SOP任务, 大大提升了模型的能力.
- AlBERT模型发现了dropout操作的负面作用.
- AlBERT在训练语句的长度上更倾向于长文本, 同时优化了Masked-Ngram-LM的训练细节.
- albert-tiny模型非常轻巧, 在语义相似度, 分类等工业场景下可以大大提升推理速度.