3.2 数据并行DP
数据并行原理
学习目标
- 理解数据并行DP的原理.
- 理解分布式数据并行DDP的原理.
数据并行
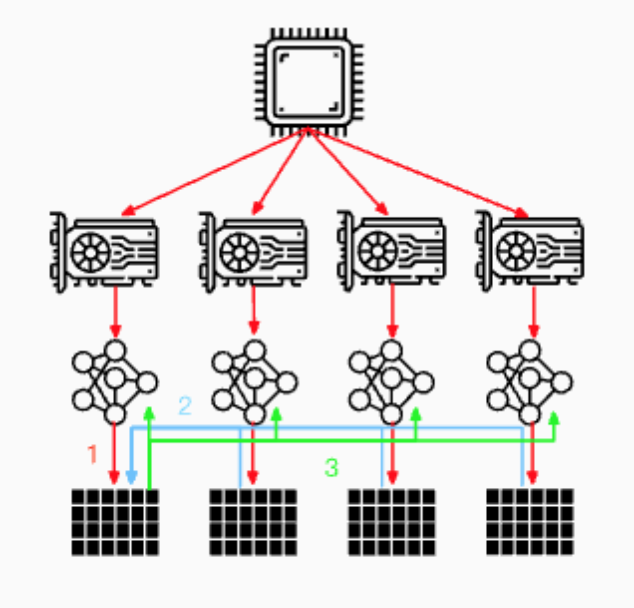
- 所谓数据并行, 就是由于训练数据集太大, 因此将数据集分为N份, 每一份分别装载到N个GPU节点中. 同时, 每个GPU节点持有一个完整的模型副本, 分别基于每个GPU中的数据去进行梯度求导. 然后, 在GPU0上对每个GPU中的梯度进行累加. 最后, 再将GPU0聚合后的结果广播到其他GPU节点, 如下图所示:
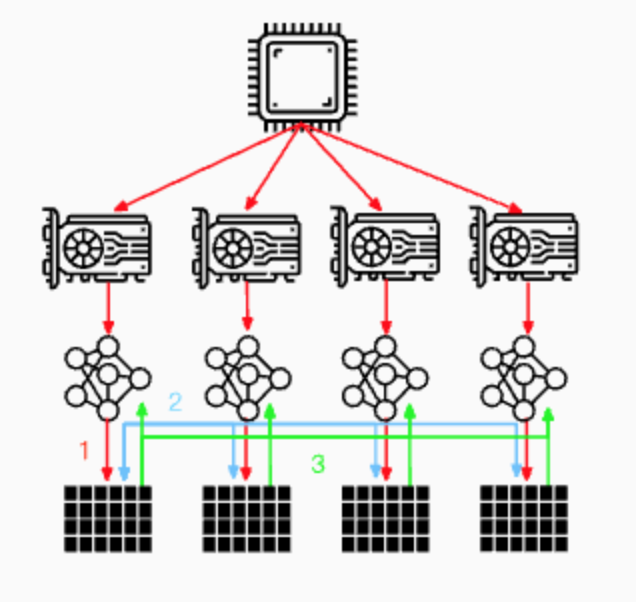
- 当然, 也可以将参数服务器分布在所有GPU节点上面, 每个GPU只更新其中一部分梯度, 如下图所示:
数据并行Pytorch DP
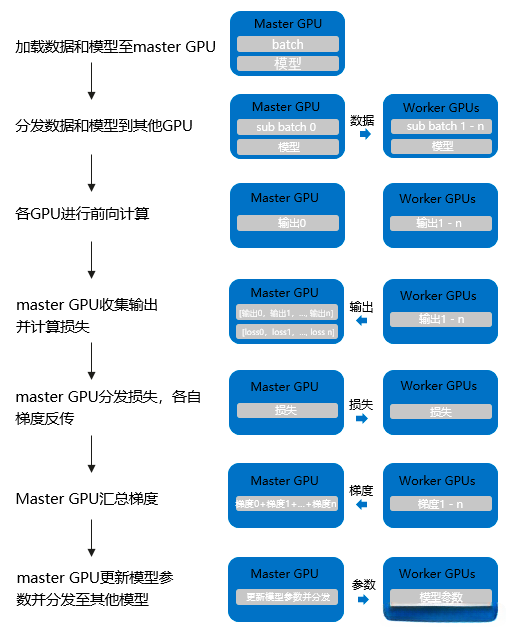
- 数据并行的流程: 数据并行(torch.nn.DataParallel), 这是Pytorch最早提供的一种数据并行方式, 它基于单进程多线程进行实现的, 它使用一个进程来计算模型权重, 在每个批处理期间将数据分发到每个GPU:
- 1: 将inputs从主GPU分发到所有GPU上.
- 2: 将model从主GPU分发到所有GPU上.
- 3: 每个GPU分别独立进行前向传播, 得到outputs.
- 4: 将每个GPU的outputs发回主GPU.
- 5: 在主GPU上, 通过loss function计算出loss, 对loss function求导, 求出损失梯度.
- 6: 计算得到的梯度分发到所有GPU上.
- 7: 反向传播计算参数梯度.
- 8: 将所有梯度回传到主GPU, 通过梯度更新模型权重.
- 9: 不断重复上面的过程.
# 将数据和模型分布式放在0号GPU, 1号GPU, 2号GPU上.
net = torch.nn.DataParallel(model, device_ids=[0, 1, 2])
# input_var can be on any device, including CPU
output = net(input_var)
- Pytorch DP的缺点:
- 单进程多线程带来的问题: DataParallel使用单进程多线程进行实现的, 方便了信息的交换, 但受困于GIL, 会带来性能开销, 速度很慢. 而且, 只能在单台服务器(单机多卡)上使用(不支持分布式). 同时, 不能使用Apex进行混合精度训练.
- 效率问题: 主卡性能和通信开销容易成为瓶颈, GPU利用率通常很低, 数据集需要先拷贝到主进程, 然后再分片(split)到每个设备上; 权重参数只在主卡(GPU0)上更新, 需要每次迭代前向所有设备做一次同步; 每次迭代的网络输出需要聚集到主卡(GPU0)上. 所以通信很快成为一个瓶颈. 除此之外, 这将导致主卡和其他卡之间, GPU利用率严重不均衡(比如主卡使用了10G显存, 而其他卡只使用了2G显存, batch size稍微设置大一点主卡的显存就OOM了).
- 不支持模型并行, 由于其本身的局限性, 没办法与模型并行组合使用.
- 注意: 目前PyTorch官方建议使用DistributedDataParallel, 而不是DataParallel类来进行多GPU训练, 即使在单机多卡的情况下!!!
分布式数据并行Pytorch DDP
- 分布式数据并行(torch.nn.DistributedDataParallel), 基于多进程进行实现的, 每个进程都有独立的优化器, 执行自己的更新过程. 每个进程都执行相同的任务, 并且每个进程都与所有其他进程通信. 进程(GPU)之间只传递梯度, 这样网络通信就不再是瓶颈.
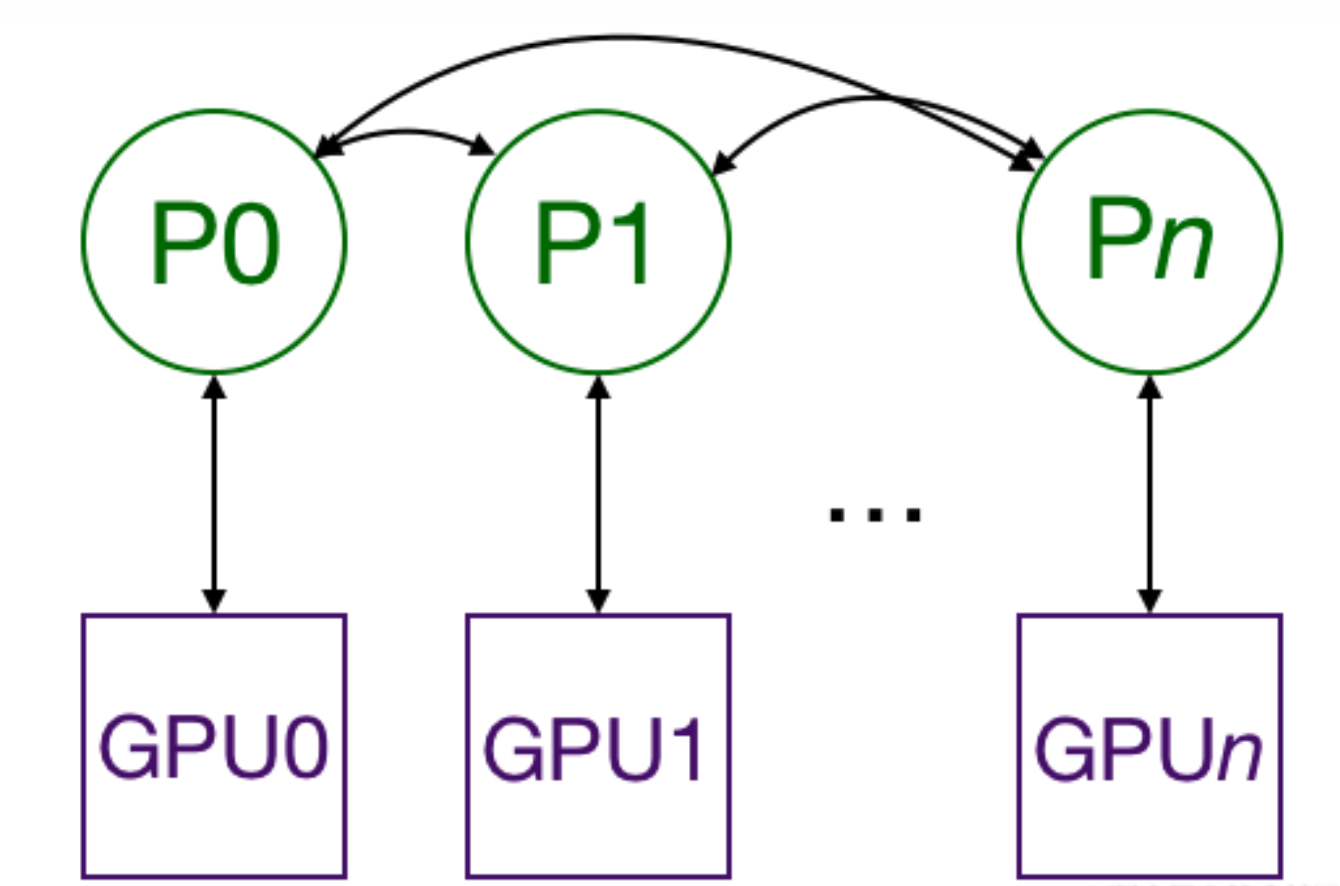
- Pytorch DDP具体流程:
- 1: 首先将rank=0进程中的模型参数广播到进程组中的其他进程.
- 2: 每个DDP进程都会创建一个local Reducer来负责梯度同步.
- 3: 在训练过程中, 每个进程从磁盘加载batch数据, 并将它们传递到其GPU. 每个GPU都有自己的前向过程, 完成前向传播后, 梯度在各个GPUs间进行All-Reduce, 每个GPU都收到其他GPU的梯度, 从而可以独自进行反向传播和参数更新.
- 4: 同时, 每一层的梯度不依赖于前一层, 所以梯度的All Reduce和后向过程同时计算, 以进一步缓解网络瓶颈.
- 5: 在后向过程的最后, 每个节点都得到了平均梯度, 这样各个GPU中的模型参数保持同步.
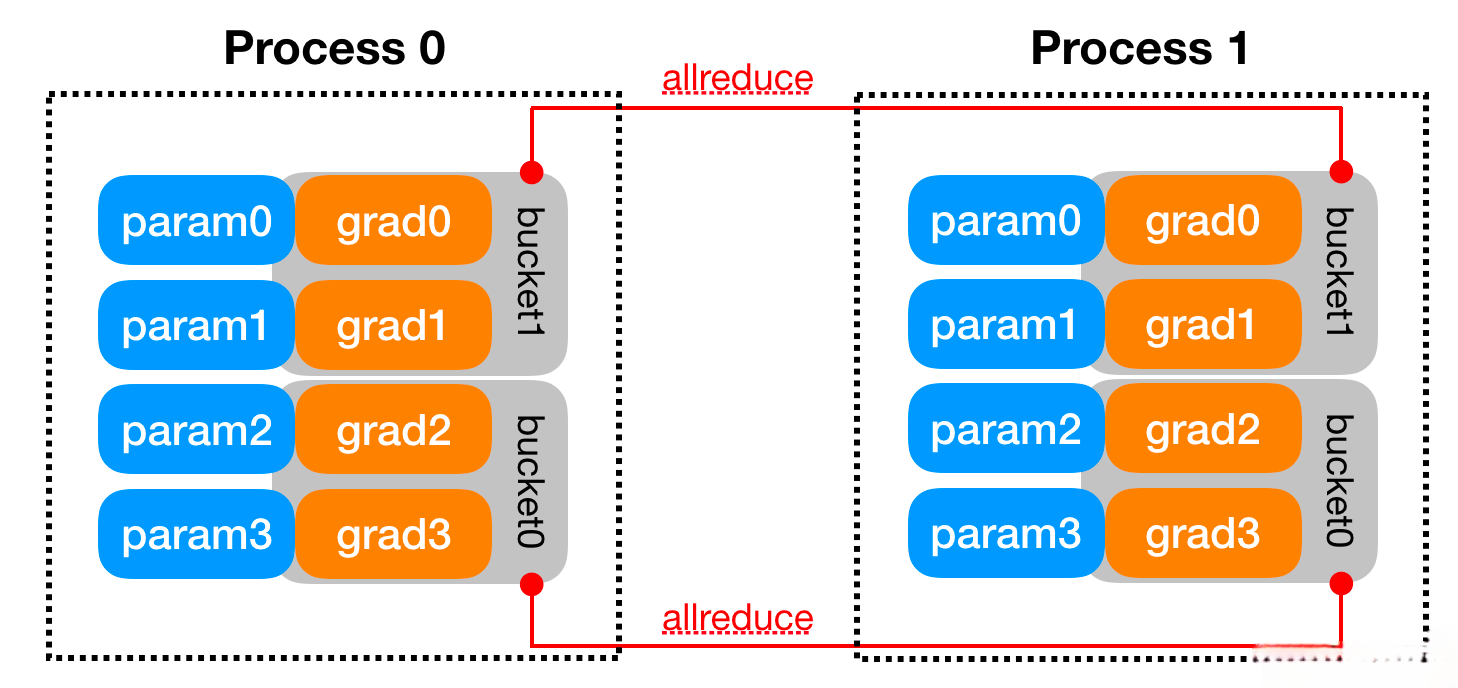
- 注意: DataParallel是将梯度reduce到主卡, 在主卡上更新参数, 再将参数broadcast给其他GPU, 这样无论是主卡的负载还是通信开销都比DDP大很多). 相比于DataParallel, DistributedDataParallel方式可以更好地进行多机多卡运算, 更好的进行负载均衡, 运行效率也更高, 虽然使用起来较为麻烦, 但对于追求性能来讲是一个更好的选择.
# 使用torch.nn.Linear作为本地模型, 用DDP对其进行包装,
# 然后在DDP模型上运行一次前向传播, 一次反向传播和更新优化器参数步骤.
# 之后, 本地模型上的参数将被更新, 并且不同进程上的所有模型完全相同.
import torch
import dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
def example(rank, world_size):
# 创建进程组
dist.init_process_group("gloo", rank=rank, world_size=world_size)
# 实例化本地模型
model = nn.Linear(10, 10).to(rank)
# 实例化DDP模型对象
ddp_model = DDP(model, device_ids=[rank])
# 定义损失函数和优化器
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
# 前向计算
outputs = ddp_model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
# 反向传播
loss_fn(outputs, labels).backward()
# 参数更新
optimizer.step()
def main():
world_size = 2
mp.spawn(example, args=(world_size,), nprocs=world_size, join=True)
if __name__ == '__main__':
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "29500"
main()
DP与DDP的区别
- DP与DDP的主要区别有如下几点:
- DP是基于单进程多线程的实现, 只用于单机情况, 而DDP是多进程实现的, 每个GPU对应一个进程, 适用于单机和多机情况, 是真正实现分布式训练. 并且因为每个进程都是独立的Python解释器, DDP避免了GIL带来的性能开销.
- 参数更新的方式不同, DDP在各进程梯度计算完成之后, 各进程需要将梯度进行汇总平均, 然后再由rank=0的进程, 将其广播到所有进程后, 各进程用该梯度来独立的更新参数(而DP是梯度汇总到GPU0, 反向传播更新参数, 再广播参数给其他剩余的GPU). 由于DDP各进程中的模型, 初始参数一致(初始时刻进行一次广播), 而每次用于更新参数的梯度也一致; 因此, 各进程的模型参数始终保持一致(而在DP中, 全程维护一个optimizer, 对各个GPU上梯度进行求平均, 而在主卡进行参数更新, 之后再将模型参数广播到其他GPU). 相较于DP, DDP传输的数据量更少, 训练更高效, 不存在DP中负载不均衡的问题. 目前, 基本上DP已经被弃用.
- DDP支持模型并行, 而DP并不支持, 这意味如果模型太大单卡显存不足时, 只能使用DDP.
- DP数据传输过程:
- 1: 前向传播得到的输出结果gather到主cuda计算loss.
- 2: scatter上述loss到各个cuda.
- 3: 各个cuda反向传播计算得到梯度后gather到主cuda后, 主cuda的模型参数被更新.
- 4: 主cuda将模型参数broadcast到其它cuda设备上, 至此, 完成权重参数值的同步.
- DDP数据传输过程:
- 1: 前向传播的输出和loss的计算都是在每个cuda独立计算的.
- 2: 梯度all-reduce到所有的CUDA(传输梯度).
- 3: 这样初始参数相同, para.grad也相同, 反向传播后参数就还是保持一致的.