3.1 流水线并行PP
流水线并行¶
学习目标¶
- 理解流水线并行的底层原理
大模型分布式训练的并行技术¶
- 近年来, 随着Transformer, MoE架构的提出, 使得深度学习模型轻松突破上万亿规模参数. 传统的单机单卡模式已经无法满足超大模型进行训练的要求. 因此, 我们需要基于单机多卡, 多机多卡来进行分布式大模型的训练.
- 利用AI集群, 使得深度学习算法更好地从大量数据中高效训练出性能优异的大模型是分布式机器学习的首要目标. 为了实现该目标, 一般需要根据硬件资源与数据(模型)规模的匹配情况, 考虑对计算任务, 训练数据和模型进行划分, 从而进行分布式存储和分布式训练. 本章我们就深入分析一下背后的原理.
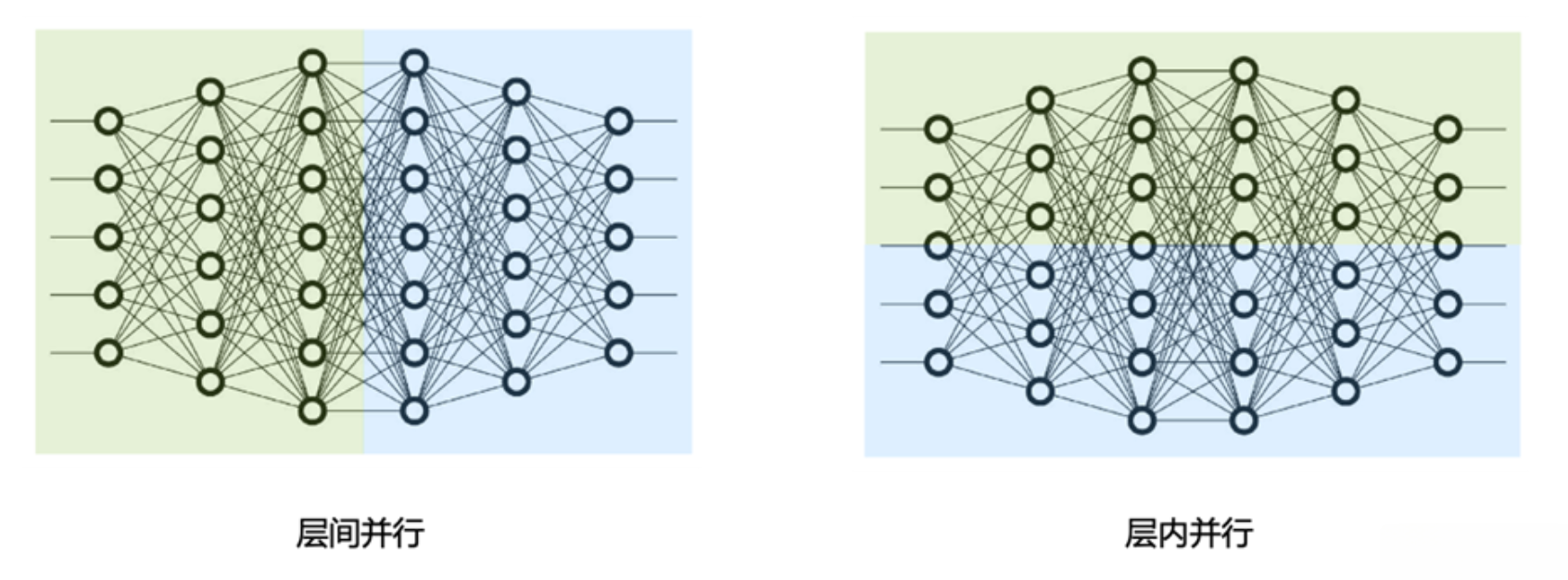
- 首先, 大模型的并行技术分为张量并行(TP: Tensor Parallel), 和流水线并行(PP: Pipeline Parallel), 如下图所示:
- 张量并行(TP, 右图): 张量并行为层内并行, 对模型Transformer层内进行分割.
- 流水线并行(PP, 左图): 流水线并行为层间并行, 对模型Transformer不同层间进行分割.
流水线并行¶
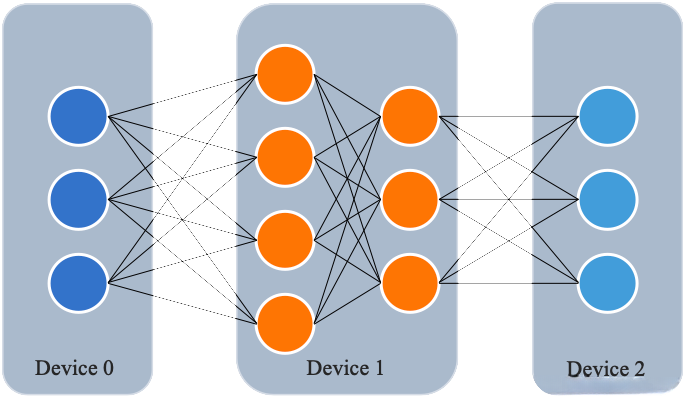
- 流水线并行, 是因为模型太大, 无法将整个模型放置到单张GPU卡中, 所以将模型的不同层放置到不同的计算设备, 降低单个计算设备的显存消耗, 从而实现超大规模模型的训练.
- 如下图所示: 模型总共包含4个模型层, 被切分成3个部分, 分别放置到3个不同的计算设备上. 第1层放置到Device 0, 第2层和第3层放置到Device 1上, 第4层放置到Device 2上.
-
相邻设备间通过通信链路传输数据, 具体来说, 前向计算过程中, 输入数据首先在设备0上通过第1层的计算得到中间结果, 并将中间结果传输到设备1, 然后再设备1上计算得到第2层和第3层的输出, 并将模型第3层的输出结果传输到设备2, 在设备2上经由最后一层的计算得到前向计算结果.
-
反向传播的过程类似.
-
最后各个设备上的网络层会使用反向传播过程计算得到的梯度更新参数. 由于各个设备之间传输的仅仅是相邻设备间的输出张量, 而不是梯度信息, 因此通信量较小.
朴素流水线并行¶
- 朴素流水线并行是实现流水线并行训练的最直接的方式. 我们将模型按照层间切分成多个部分(Stage), 并将每个部分(Stage)分配给一个GPU. 然后我们对小批量数据进行常规的训练, 在模型切分成多个部分的边界处进行通信.
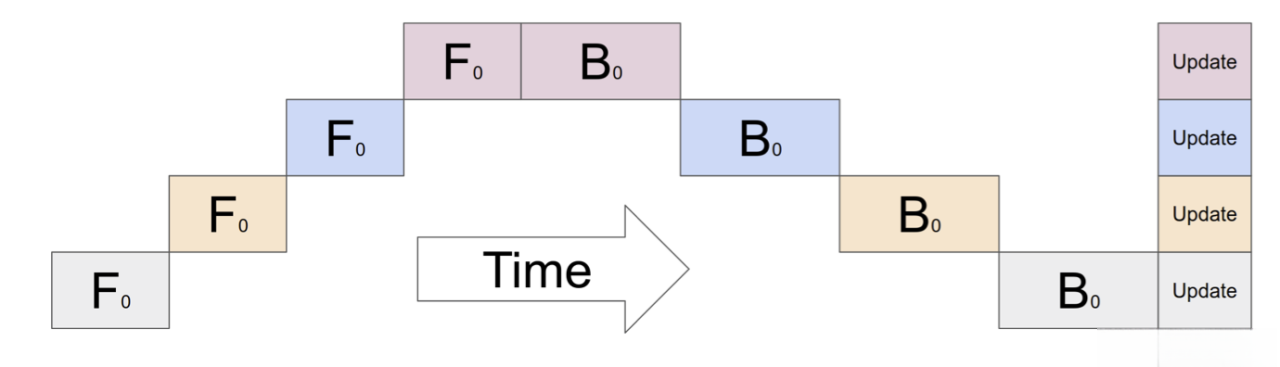
- 以4层模型举一个栗子🌰:
output = L4(L3(L2(L1(input))))
- 将计算分配给2个GPU, 如下所示:
GPU1: intermediate=L2(L1(input))
GPU2: output=L4(L3(intermediate))
- 为了完成前向传播, 在GPU1上计算中间值并将结果张量传输到GPU2. 然后, GPU2计算模型的输出并开始进行反向传播. 对于反向传播, 我们从GPU2到GPU1的中间发送梯度. 然后, GPU1根据发送的梯度完成反向传播. 这样流水线并行训练会产生与单节点训练相同的输出和梯度. 朴素流水线并行训练相当于顺序训练, 这使得调试变得更加容易.
- 如下图所示, 展示了朴素流水线的并行执行流程: GPU1执行前向计算并缓存激活(红色). 然后, 它使用MPI将L2的输出发送到GPU2. GPU2完成前向计算, 并使用目标值计算损失, 完成后开始反向传播. 一旦GPU2完成, 梯度的输出被发送到GPU1, 从而完成反向传播.
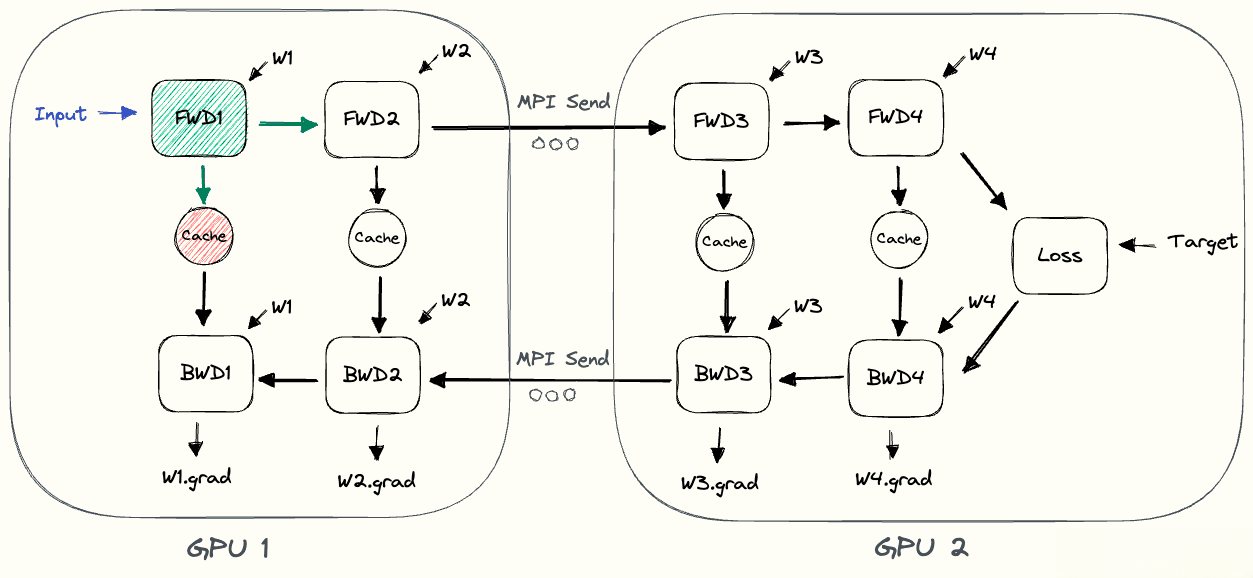
- 注意: 这里仅用到点到点通信(MPI.Send和MPI.Recv), 并且不需要任何集体通信源于(因此不需要MPI.AllReduce).